Phase II - Data preparation/engineering
Course: MLOps engineering
Author: Firas Jolha
Dataset
Agenda
- Phase II - Data preparation/engineering
- Dataset
- Agenda
- Description
- Docker and Docker compose [Extra section for now]
- Apache Airflow
- ZenML
- Feast [Extra section]
- Project tasks
- References
Description
The second phase of the CRISP-ML process model aims to prepare data for the following modeling phase. Data selection, data cleaning, feature engineering, and data standardization tasks are performed during this phase.
We identify valuable and necessary features for future model training by using either filter methods, wrapper methods, or embedded methods for data selection. Furthermore, we select data by discarding samples that do not satisfy data quality requirements. At this point, we also might tackle the problem of unbalanced classes by applying over-sampling or under-sampling strategies.
The data cleaning task implies that we perform error detection and error correction steps for the available data. Adding unit testing for data will mitigate the risk of error propagation to the next phase. Depending on the machine learning task, we might need to perform feature engineering and data augmentation activities. For example, such methods include one-hot encoding, clustering, or discretization of continuous attributes.
The data standardization task denotes the process of unifying the ML tools’ input data to avoid the risk of erroneous data. Finally, the normalization task will mitigate the risk of bias to features on larger scales. We build data and input data transformation pipelines for data pre-processing and feature creation to ensure the ML application’s reproducibility during this phase.
In the 2nd phase of the project, we will transform the data and prepare it for ML modeling. The objective here is to have automated pipelines which can start extracting the data from the data source till persisting the features in some feature store.

Data preparation is not a static phase and backtracking circles from later phases are necessary if, for example, the modeling phase or the deployment phase reveal erroneous data. So, we need to automate the data preparation pipelines.
Note:
The commands and scripts here are written considering by default that the Current Working Directory (CWD) is the project folder path. So ensure that you are there before you run commands. In my PC, I have ~/project folder in my home directory which is the project folder path and it is also the CWD unless the directory is changed using cd.
Docker and Docker compose [Extra section for now]
This section is extra for now but will be mandatory in phase 5 of CRISP-ML.
Docker is a set of platform as a service (PaaS) products that use OS-level virtualization to deliver software in packages called containers.
In simpler words, Docker is a tool that allows to easily deploy the applications in a sandbox (called containers) to run on the host operating system i.e. Linux.
The key benefit of Docker is that it allows users to package an application with all of its dependencies into a standardized unit for software development. Unlike virtual machines, containers do not have high overhead and hence enable more efficient usage of the underlying system and resources.
The industry standard today is to use Virtual Machines (VMs) to run software applications. VMs run applications inside a guest Operating System, which runs on virtual hardware powered by the server’s host OS.
VMs are great at providing full process isolation for applications: there are very few ways a problem in the host operating system can affect the software running in the guest operating system, and vice-versa. But this isolation comes at great cost — the computational overhead spent virtualizing hardware for a guest OS to use is substantial.
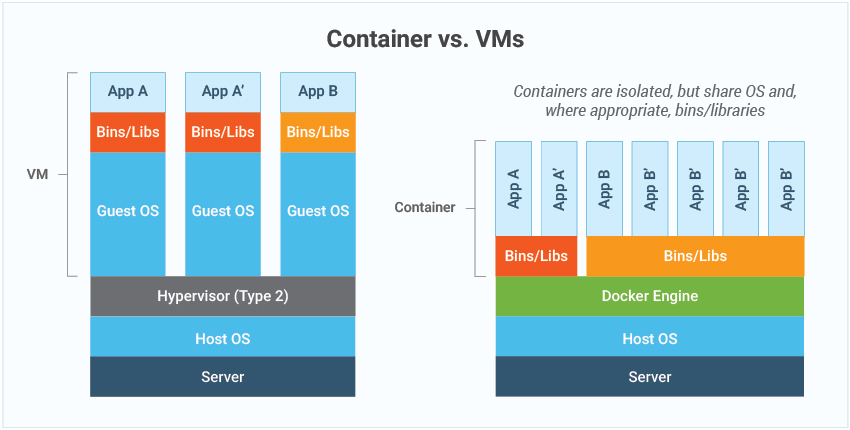
Containers take a different approach, by leveraging the low-level mechanics of the host operating system, containers provide most of the isolation of virtual machines at a fraction of the computing power.
- Dockerfile is a simple text file that contains a list of instructions that the Docker client calls while creating an image.

- Docker image is an artifact with several layers and a lightweight, compact stand-alone executable package that contains all of the components required to run a piece of software, including the code, a runtime, libraries, environment variables, and configuration files.
- Docker container is a runtime instance of an image.
Install docker and docker compose
The official website has a good tutorial to download and install both tools. I share here some of the tutorials:
After you install the tools, use the docker command to run hello-world container as follows:
docker run hello-world
This command line will download the docker image hello-world for the first time and run a container.
Note: If docker is not running due to restrictions in Russia, then add a mirror to the configuration of the docker daemon (daemon.json). The guide is in this link https://dockerhub.timeweb.cloud/.

Dockerfile definition [extra section]
Dockerfile contains the instructions to build a Docker image.
# Represents the base image, which is the command that is executed first before any other commands.
FROM <ImageName>
# used to copy the file/folders to the image while building the image.
# Source; is the location of the file/folders in the host machine
# Destination: is the location of the file/folders in the container
COPY <Source> <Destination>
# does the same as COPY. Additionally it lets you use URL location to download files and unzip files into the image
ADD <URL> <Destination>
# Runs scripts and commands in the container. The execution of RUN commands will take place while you create an image on top of the prior layers (Image). It is used to install packages into container, create folders, etc
RUN <Command + ARGS>
# allows you to set a default command which will be executed only when you run a container without specifying a command. If a Docker container runs with a command, the default command will be ignored, so it can be overridden. There can be only one CMD in the dockerfile.
CMD [command + args]
# A container that will function as an executable is configured by ENTRYPOINT. When you start the Docker container, a command or script called ENTRYPOINT is executed. It ca not be overridden.The only difference between CMD and ENTRYPOINT is CMD can be overridden and ENTRYPOINT can’t.
ENTRYPOINT [command + args]
# identifies the author/owner of the Dockerfile
MAINTAINER <NAME>
# sets environment variables inside the container
ENV VAR VALUE
# defines build-time variable.
ARG VAR VALUE
# info to expose ports outside the container
EXPOSE PORT
# info to create a directory mount point to access and store persistent data
# PATH here is container path
VOLUME [PATH]
# sets the working directory for the instructions that follow
WORKDIR SOME_CONTAINER_PATH
Demo
Here we will create a simple Flask app, dockerize it and push it to Docker hub.
- Prepare the following files.
- requirements.txt: contains the app dependencies.
- app.py: contains the Flask app code.
- Dockerfile: contains the instructions to build a Docker image.
# requirements.txt
flask
# app.py
from flask import Flask
import os
app = Flask(__name__)
@app.route("/")
def hello():
return "Hello World!"
if __name__ == "__main__":
port = int(os.environ.get('PORT', 5000))
app.run(debug=True, host='0.0.0.0', port=port)
# Dockerfile
# Base image
FROM python:3.8-alpine
# Switch to another directory
# CWD is /usr/src/app
WORKDIR /usr/src/app
# Copy the requirements.txt to CWD
COPY requirements.txt ./
# Install the dependencies in requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Copy the code and everything in CWD of the host to CWD of the container
COPY . .
# Make the Docker container executable
ENTRYPOINT ["python"]
# Specify the default command line argument for the entrypoint
CMD ["app.py"]
# This will be based to the default entry point
# CMD [ "python", "./app.py" ]
- Build the image with tag
flask_webservice.
docker build -t flask_webservice .
- Run the container on port 5000. Add a name to the container
flask_webservice.
docker run -d -p 5000:5000 --name test_webservice flask_webservice
The option -p is used to map ports between the host and the container. The option -d is used to detach the shell from the container such that it will run in the background and will not block the shell.
- Some other commands.
# Stops the container
docker stop <container-id-name>
# Stops the container
docker rm <container-id-name>
# shows all running containers
docker ps
- Add a volume if you are debugging the application.
docker run -p 5000:5000 --name test_service -v .:/usr/src/app --rm flask_webservice
A Docker volume is an independent file system entirely managed by Docker and exists as a normal file or directory on the host, where data is persisted.
- Create a repository on Docker hub

- Log in on your local machine
docker login
Enter the username and password.
- Rename the docker image
docker tag flask_webservice firasj/dummy_flask_service:v1.0
- Push to Docker Hub
docker push firasj/dummy_flask_service:v1.0
Whenever you made changes, you can build then push another version/tag to Docker hub.
- Access the container via terminal
docker exec -i -t test_service bash
If you pass to the previous command app.py instead of bash, then the container will run the python as follows:
python app.py
If we pass a different application app2.py, the container will run the python as follows:
python app2.py
If the docker command asks for sudo permission everytime you use it, run the following:
sudo chmod 777 /var/run/docker.sock
This will give permissions to everyone to run docker (could be risky for multi-user environments).
Docker Compose
Docker Compose is a tool for defining and running multi-container applications.
You can find below some tutorials to learn Docker and Docker compose.
https://learnxinyminutes.com/docs/docker/
A tutorial to learn Docker
https://docker-curriculum.com/#docker-compose
A tutorial to learn Docker compose
You can run Apache Airflow using docker and docker compose. Example on docker and docker compose is below this section.
Apache Airflow
Apache Airflow™ is an open-source platform for developing, scheduling, and monitoring batch-oriented workflows. The main characteristic of Airflow workflows is that all workflows are defined in Python code, such that “Workflows as code”. It started in 2014 at Airbnb, and is written in Python.

Airflow is a platform that lets you build and run workflows. A workflow is represented as a DAG (a Directed Acyclic Graph), and contains individual pieces of work called Tasks, arranged with dependencies and “data” flows taken into account. Airflow™ is a batch workflow orchestration platform.
Install Airflow
There are multiple ways to install Aapch Airflow, but here we will demonstrate only pip and Docker mathods.
1. Usingpip
Apache Airflow has no support for Windows platform and we need to find a way to run it using Docker or WSL2. For Linux users. the installation is easier.
Windows user
We will use WSL2 system to run Airflow. You need to install WSL2 with the Ubuntu distro.
This step is important for Windows users as some tools do not support Windows platform such as feast and airflow.
You need to follow the steps below:
- Follow this tutorial to install WSL2 and Ubuntu on Windows. Open Ubuntu app (terminal) on your Windows and configure the username and password. This user has sudo permission and root user is not needed.
- Install git on Ubuntu if not installed. Clone your project repository to some folder (e.g.
~/projectin my PC). - Open the project local repository in VS Code by executing
code <project-folder-path> # OR # Example cd <project-folder-path> code . # if you are already in the project local repository
After that, follow the section Prepare the workspace.
Linux user
For Linux users, nothing special here, they just need to go to set up their workspace from here.
2. Using Docker
- I recommend to follow the first approach (using pip) as every tool will run on the same system but if you prefer this method (with additional efforts), you can try. You need to manage here two OSes and need to install Python packages on both of them.
- Make sure that the version of Docker image for Apache Airflow is the same as the package version in your virtual environment in VS code. I recommend the Airflow version
2.7.3due to its compatibility with the dependencies of other tools. If you installed more recent versions, you may face issues (conflicts of dependencies).
The airflow.Dockerfile contains the instructions to build a configured image of Apache Airflow.
# The base image - Use the same version of the package `apache-airflow` that you installed via pip
FROM apache/airflow:2.7.3-python3.11
# FROM apache/airflow:latest-python3.11
# FROM apache/airflow:2.9.2-python3.11
# Why python3.11? the explanation is later below
# Set CWD inside the container
WORKDIR /project
# This will be the project folder inside the container
# Copy requirements file
COPY airflow.requirements.txt .
# Install requirements.txt
RUN pip install -r airflow.requirements.txt --upgrade
# Switch to root user
USER root
# Install some more CLIs
RUN apt-get update \
&& apt-get install -y --no-install-recommends vim curl git rsync unzip \
&& apt-get autoremove -y \
&& apt-get clean
# EXPOSE 8080
# Switch to regular user airflow
USER airflow
# Run this command when we start the container
CMD ["airflow", "standalone"]
The following file airflow.docker-compose.yaml contains all instructions needed to spin up a docker container to run Airflow components.
# airflow.docker-compose.yaml
# declare a dict of services
services:
# Airflow service
airflow:
# Container name of thes service
container_name: "airflow_service"
# base image
# image: apache/airflow:latest
# Build the custom image
build:
context: .
dockerfile: airflow.Dockerfile
# Always restart the container if it stops.
# If it's manually stopped, it's restarted
# only when Docker daemon restarts or the container itself is manually restarted.
restart: always
# Env variables to be used inside the container
environment:
# The home directory of Airflow inside the container
AIRFLOW_HOME : /project/services/airflow
# The directories of source code and scripts in the project
# These locations will be added to let airflow see our files
PYTHONPATH : /project/src:/project/scripts
# A custom environment variable to our project directory
PROJECTPATH: /project
# Allows to create volumes
volumes:
# Creates a volume for airflow metadata
- ./services/airflow:/opt/airflow
# Creates a volume to store the project in the container
- .:/project
ports:
# Used to map ports from host to guest (container)
- 8080:8080
# Command to run when we start the container
# We do not need this since we have it in airflow.Dockerfile
# command: airflow standalone
Run the container
sudo docker-compose -f airflow.docker-compose.yaml up -d --build
You can access the web server in (http://localhost:8080). If the port 8080 is not free, then assign it to another port, for instance (8081:8080).
The default username is admin and the password is randomly generated and stored in ./services/airflow/standalone_admin_password.txt.
Linux gurus
If you used the Docker approach with Linux systems, you may have some issues with access permission to files. Make sure that the UID of the user running the docker commands the same UID inside the docker container. Check this (https://github.com/puckel/docker-airflow/issues/224).
In linux systems, you have to create some folders in advance for the volumes you mounted. Check this (https://airflow.apache.org/docs/apache-airflow/stable/howto/docker-compose/index.html#initializing-environment)
Info:
- If you have good hardware resources, then you can run the production-ready docker compose file from https://airflow.apache.org/docs/apache-airflow/2.9.2/docker-compose.yaml.
- This will create a multi-container cluster to run a docker container for each of the Airflow components.
Prepare the workspace [tested on Ubuntu 22.04]
Whether you followed pip or Docker method, you need to set up your workspace to run all required tools properly. The steps are:
1. Install python3.11
Install python3.11 and python3.11-venv on your system (Ubuntu in my case) before running any Airflow component.
sudo apt update
# install Python 3.11
sudo apt install python3.11
# instal Python 3.11 for creating virtual environments
sudo apt install python3.11-venv
We are using Python 3.11 here and not 3.12 or 3.13 since some tools such as zenml do not support Python versions higher than 3.11.
2. Create a new virtual environment using Python 3.11
# Create .venv
python3.11 -m venv .venv
# Activate it
source .venv/bin/activate
# You can deactivate it at anytime
# deactivate
3. Create requirements.txt and install the dependencies.
# requirements.txt
# HERE I added all possible tools that you will probably use in the project
zenml[server]
apache-airflow
feast
great_expectations
dvc
hydra-core
pytest
pandas
scikit-learn
pendulum
shyaml
mlflow
giskard
evidently
Flask
flask-session2
psycopg2-binary
# tensorflow # If you are Master's student
# torch # If you are Master's student
pip install -r requirements.txt --upgrade
- Do not use
--upgradeif you do not want to change in the installed packages. - Omitting this option, may introduce some conflicts with other packages (be careful).
When you want to install a new package, add it to requirements.txt and run the previous commnd again. Do not install packages, one by one as you may face dependency conflicts. In summary, you need to keep all your packages without conflicts.
Important notes:
- Before running Airflow. We need to customize the Airflow config folder as follows.
# PWD is project folder path export AIRFLOW_HOME=$PWD/services/airflow - Make sure that you set this environment variable before you work with Airflow. This will store the configs and metadata in the specified folder. This folder needs to be pushed to Github.
- Add this to your
~/.bashrcfile as a permanent variable but replace$PWDwith your absolute project folder path.# REPLACE <project-folder-path> with your project folder path cd <project-folder-path> echo "export AIRFLOW_HOME=$PWD/services/airflow" >> ~/.bashrc # Run/Load the file content source ~/.bashrc # Activate the virtual environment again source .venv/bin/activate- You do this only once, then the variable will be loaded everytime you open a new terminal.
4. Setup the Airflow components
4.1. Setup Metadata database and Executor
4.1.A. Minimal setup (SequentialExecutor + SQLite)
- Initialize the metadata database (SQLite)
# Clean it
# Caution: this will delete everything
airflow db reset
# initialize the metadata database
airflow db init
Note:
This minimal setup of Airflow will use SequentialExecutor which runs only a single thread, so you cannot run more than one task at the same time. The database is a lightweight sqlite database. The drawback here is mainly related to the performance and resilience of Airflow components. You may face issues such as connection timeout for database, the scheduler is unhealthy (need to restart it), more waiting time for DAG runs since only one thread is allowed here.
4.1.B. Normal setup (LocalExecutor + PostgreSQL)
- Install PostgreSQL on your PC.
sudo apt-get install postgresql
The output:
firasj@Lenovo:~$ sudo apt-get install postgresql
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
Suggested packages:
postgresql-doc
The following NEW packages will be installed:
postgresql
0 upgraded, 1 newly installed, 0 to remove and 50 not upgraded.
Need to get 0 B/3288 B of archives.
After this operation, 71.7 kB of additional disk space will be used.
Selecting previously unselected package postgresql.
(Reading database ... 37631 files and directories currently installed.)
Preparing to unpack .../postgresql_14+238_all.deb ...
Unpacking postgresql (14+238) ...
Setting up postgresql (14+238) ...
- Run PostgreSQL service
sudo systemctl start postgresql
The output:
firasj@Lenovo:~$ sudo systemctl start postgresql
- Create a database user for you
- Access the
psqlCLI as defaultpostgresuser
firasj@Lenovo:~$ sudo -u postgres psql psql (14.12 (Ubuntu 14.12-0ubuntu0.22.04.1)) Type "help" for help. postgres=#- Create a database user for you (
firasjin my PC)
postgres=# CREATE USER firasj WITH PASSWORD 'firasj'; - Access the
- Create a database
aiflow
postgres=# CREATE DATABASE airflow;
- Give permissions to the database user (
firasjin my PC).
postgres=# GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA public TO firasj;
- Check that the database user is created.
postgres=# \du
List of roles
Role name | Attributes | Member of
-----------+------------------------------------------------------------+-----------
firasj | | {}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
- Close the connection
postgres=# \q
- Configure Postgresql permissions
# 1. Open this file
sudo nano /etc/postgresql/14/main/pg_hba.conf
# 2. Add the following line to the end of this file
host all all 0.0.0.0/0 trust
# 3. Save the change and close it
# 4. Open another file
sudo nano /etc/postgresql/14/main/postgresql.conf
# 5. Add the line as follows
#------------------------------------------------------------------------------
# CONNECTIONS AND AUTHENTICATION
#------------------------------------------------------------------------------
# - Connection Settings -
listen_addresses = '*'
# 6. Save the change and close it
- Restart PostgreSQL service
firasj@Lenovo:~$ sudo systemctl restart postgresql
- Initialize the default database (SQLite).
# Set home directory of Airflow
export AIRFLOW_HOME=$PWD/services/airflow
# Actiavte the virtual env
source .venv/bin/activate
# Initialize the database
airflow db init
- Configure the Airflow.
# 1. Go to the file `./services/airflow/airflow.cfg` in VS Code
# 2. Change the executor
executor = LocalExecutor # line 45 in version 2.7.3
# 3. Change the database connection
# line 424 in version 2.7.3
sql_alchemy_conn = postgresql+psycopg2://firasj:firasj@localhost:5432/airflow
# This connection string has the following format
# postgresql+psycopg2://<db_user>:<db_user_password>@<hostname>:<port_number>/<database_name>
- Initialize the metadata database (PostgreSQL)
# Clean it
# Caution: this will delete everything
airflow db reset
# initialize the metadata database
airflow db init
Now you are ready to setup your Airflow components and run them.
4.2. Setup Airflow webserver
- Create a new user and add it to the database.
# Here we are creating admin user with Admin role
airflow users create --role Admin --username admin --email admin@example.org --firstname admin --lastname admin --password admin
You can check your user from the list as follows:
airflow users list
The webserver will usually load examples of workflows, you can disable that from ./services/airflow/airflow.cfg.
# line 124 in version 2.7.3
load_examples = False
Restart the webserver to see the change if it is already running.
The default port for the Airflow webserver is 8080. You can change from the configuration file ./services/airflow/airflow.cfg.
# line 1320 in version 2.7.3
web_server_port = 8080
Restart the webserver to see the change if it is already running.
4.3. Run Airflow components
- Setup the environment and create some directories in airflow home directory.
# Add the folders which contain source codes where you want Airflow to import them for pipelines
export PYTHONPATH=$PWD/src
# You can do this also from the code via appending to sys.path
# REPLACE <project-folder-path> with your project folder path
cd <project-folder-path>
echo "export PYTHONPATH=$PWD/src" >> ~/.bashrc
# Run/Load the file content
source ~/.bashrc
# Activate the virtual environment again
source .venv/bin/activate
# Create folders and files for logging the output of components
mkdir -p $AIRFLOW_HOME/logs $AIRFLOW_HOME/dags
echo > $AIRFLOW_HOME/logs/scheduler.log
echo > $AIRFLOW_HOME/logs/triggerer.log
echo > $AIRFLOW_HOME/logs/webserver.log
# Add log files to .gitignore
echo *.log >> $AIRFLOW_HOME/logs/.gitignore
- Start the scheduler component
airflow scheduler --daemon --log-file services/airflow/logs/scheduler.log
- Start the webserver component
airflow webserver --daemon --log-file services/airflow/logs/webserver.log
- [optional] Start the triggerer component
- used to run deferrable operators
airflow triggerer --daemon --log-file services/airflow/logs/triggerer.log
- You can omit
--daemonif do not want to daemonize it. - You can omit
--log-fileif you are not interested in the log.
If you want to kill all Airflow processes/daemons in the background, run as follows:
kill $(ps -ef | grep "airflow" | awk '{print $2}')
You can access the webserver UI in (http://localhost:8080). The password is admin and username is admin if you did not change it when you created the admin user.
Important note: Restart Airflow compnents
If you terminated the Airflow components and want to run them again. Before you start the components again, you should do as follows:
- Access the project folder and activate the virtual environment.
- Set the AIRFLOW_HOME directory to the folder
./services/airflow(Where PWD is the project folder) only if you did not add it to~/.bashrc.export AIRFLOW_HOME=$PWD/services/airflow - Run the components again.
Note: If you do not do these steps then Airflow will not use the metadata and configs you defined in your airflow path (services/airflow).
Note: If you see such errors in the log of the components, such as in the scheduler
File exists: '/home/firasj/project/services/airflow/airflow-scheduler.pid'
Then delete the pid file of the component and run it again.
Notes:
-
Before you start writing DAG definition files, it is good idea to create a soft link
pipelinesto the folderservices/airflow/dagssuch that you work inpipelinesfolder and the work will be mirrored in the Airflowservices/airflow/dagsfolder to let Airflow server see our pipelines. The folderservices/airflow/dagsis the original place for storing DAGs/pipelines and it is the location where DAGs are visible to the Airflow webserver. -
You can create junction/symbolic link between folders where
pipelinesis the link andservices\airflow\dagsis the target, as follows:Windows
# You need to run this in cmd with Admin rights mklink /D /J pipelines services\airflow\dagsLinux (tested on Ubuntu 22.04)
ln -s ./services/airflow/dags ./pipelines
If the DAG is not visible in Airflow UI then, you may see import errors in the top section of the DAGs page in Airflow web UI:

Or (access the Airflow container and) run the command airflow dags list-import-errors. You can run the command airflow dags list to list all dags.
If you got such error:

Try to migrate the metadata database to the latest version as follows:
airflow db migrate
Then try to access the home page of the webserver again.
Hello world workflow
Note: Read the notes above before you build your first DAG.
# pipelines/hello_dag.py
from datetime import datetime
from airflow import DAG
from airflow.decorators import task
from airflow.operators.bash import BashOperator
# A DAG represents a workflow, a collection of tasks
# This DAG is scheduled to print 'hello world' every minute starting from 01.01.2022.
with DAG(dag_id="hello_world",
start_date=datetime(2022, 1, 1),
schedule="* * * * *") as dag:
# Tasks are represented as operators
# Use Bash operator to create a Bash task
hello = BashOperator(task_id="hello", bash_command="echo hello")
# Python task
@task()
def world():
print("world")
# Set dependencies between tasks
# First is hello task then world task
hello >> world()
In this workflow, we can see two tasks. The first one is defined using operators and the second one is defined usig @task decorator (TaskFlow API).

Core concepts
- DAG
- Directed Acyclic Graph. An Airflow DAG is a workflow defined as a graph, where all dependencies between nodes are directed and nodes do not self-reference, meaning there are no circular dependencies.
- contains individual pieces of work called Tasks, arranged with dependencies and “data” flows taken into account.
- allows to exchange data between tasks via XComs. XComs are not built for transferring large data between tasks.
- Airflow is built for orchestrating workflows and not data flows.
Data orchestration is an automated process for taking siloed data from multiple storage locations, combining and organizing it, and making it available for analysis.
We will use ZenML as data orchestrator and Airflow as workflow orchestrator.
-
DAG run
- The execution of a DAG at a specific point in time.
- A DAG run can be one of four different types:
scheduled,manual,dataset_triggeredorbackfill.
-
Operator
- A unit of work for Airflow to complete such as BashOperator, PythonOperator,…etc
- Each operator includes unique arguments for the type of work it is completing.
-
Task
- A step in a DAG describing a single unit of work.
- Determines how to execute your operator’s work within the context of a DAG
- To use an operator in a DAG, you have to instantiate it as a task.
-
Task instance
- The execution of a task at a specific point in time.
-
Airflow tasks are defined in Python code. You can define tasks using:
- Decorators(
@taskand@dag) : The recommended way to create pipelines - Traditional API (Operators and DAG)
Note
- Keep tasks as atomic as possible, meaning that each task performs a single action.
- Tasks should be idempotent, which means they produce the same output every time they are run with the same input.
- Decorators(
-
The possible states for a Task Instance are:
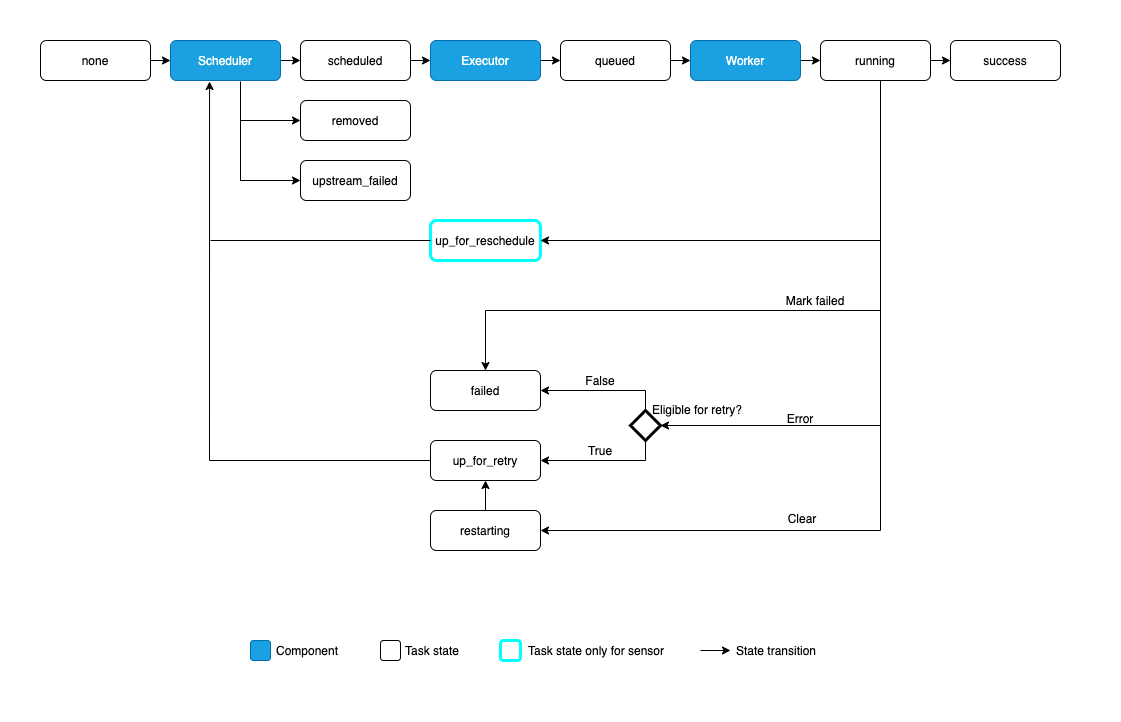
-
Special types of operators
- Sensors:
- are Operators that keep running until a certain condition is fulfilled.
- For example, the
ExternalTaskSensorwaits for a task in an external DAG to run. Sensors wait until a user defined set of criteria are fufilled.
- Deferrable Operators: [advanced topic]
- Explanation is later.
- Sensors:
-
XComs is short for cross-communication, you can use XCom to pass information between your Airflow tasks.
Airflow components
- Scheduler
- handles both triggering scheduled workflows, and submitting Tasks to the executor to run.
- The executor, is a configuration property of the scheduler, not a separate component and runs within the scheduler process.
- Webserver
- presents a handy user interface to inspect, trigger and debug the behaviour of DAGs and tasks.
- A metadata database
- used to store state of workflows and tasks.
- A folder of DAG files is read by the scheduler to figure out what tasks to run and when and to run them.
- Triggerrer [Optional]
- executes deferred tasks in an asyncio event loop.
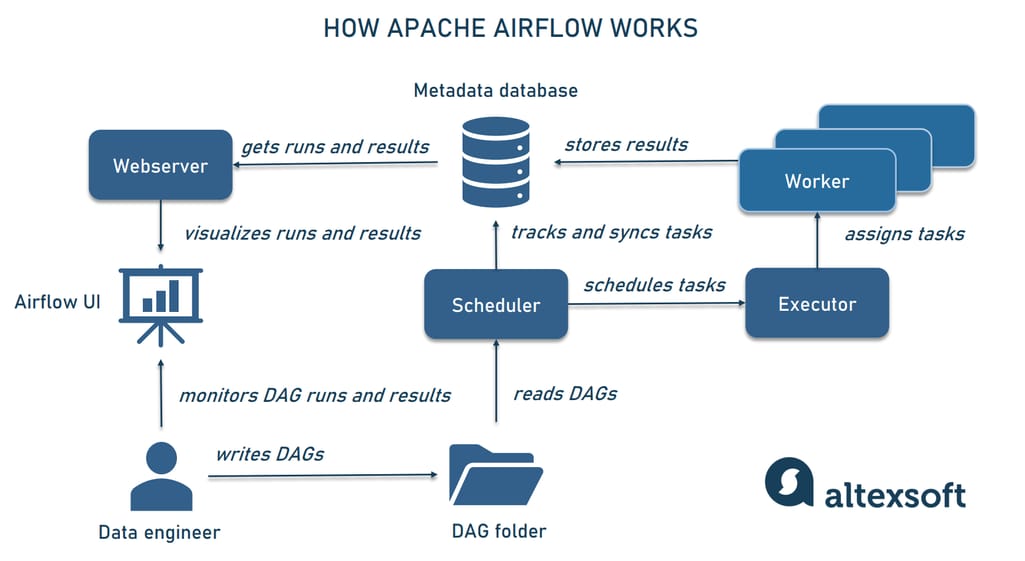
DAG Scheduling
One of the fundamental features of Apache Airflow is the ability to schedule jobs. Historically, Airflow users scheduled their DAGs by specifying a schedule with a cron expression, a timedelta object, or a preset Airflow schedule. Recent versions of Airflow have added new ways to schedule DAGs, such as data-aware scheduling with datasets.
Scheduling concepts
- Data interval: A property of each DAG run that represents the time range it operates in.
- For example, for a DAG scheduled hourly, each data interval begins at the top of the hour (minute 0) and ends at the close of the hour (minute 59). The DAG run is typically executed at the end of the data interval.
- For a DAG scheduled with @daily, for example, each of its data interval would start each day at midnight (00:00) and end at midnight (24:00).
A DAG run is usually scheduled after its associated data interval has ended, to ensure the run is able to collect all the data within the time period. In other words, a run covering the data period of 2020-01-01 generally does not start to run until 2020-01-01 has ended, i.e. after 2020-01-02 00:00:00.
- Logical Date: The start of the data interval. It does not represent when the DAG will be executed. In other words, a DAG run will only be scheduled one interval after
start_datewhich points to the same logical date.
- Run After: The earliest time the DAG can be scheduled. This date is shown in the Airflow UI, and may be the same as the end of the data interval depending on your DAG’s timetable.
- Backfilling and Catchup: are related to scheduling failed or past runs.
- Catchup: The scheduler, by default, will kick off a DAG Run for any data interval that has not been run since the last data interval (or has been cleared).
- Backfill: There can be the case when you may want to run the DAG for a specified historical period e.g., A data filling DAG is created with start_date 2019-11-21, but another user requires the output data from a month ago i.e., 2019-10-21. This process is known as Backfill. This can be done from command line as follows:
airflow dags backfill \ --start-date START_DATE \ --end-date END_DATE \ dag_id start_timeis the timestamp from which the scheduler will attempt to backfill
- DAGs scheduling parameters
data_interval_start: Defines the start date and time of the data interval. This parameter is created automatically by Airflow.data_interval_end: Defines the end date and time of the data interval. This parameter is created automatically by Airflow.schedule: Defines when a DAG will be run. The default schedule istimedelta(days=1), which runs the DAG once per day if no schedule is defined. If you trigger your DAG externally, set the schedule toNone.schedule_interval: In Airflow 2.3 and earlier, theschedule_intervalis used instead of thescheduleparameter and it only accepts cron expressions or timedelta objects.
start_date: The first date your DAG will be executed. This parameter is required for your DAG to be scheduled by Airflow.end_date: The last date your DAG will be executed. This parameter is optional.
Example
To demonstrate how these concepts work together, consider a DAG that is scheduled to run every 5 minutes as shown in the image below.
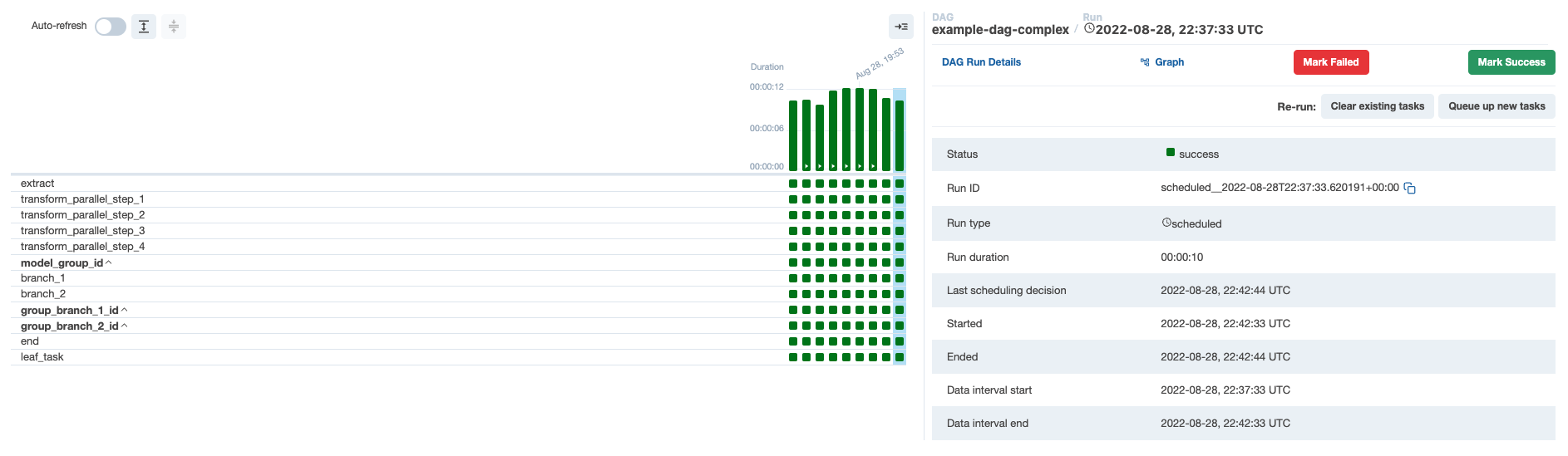
Logical date: 2022-08-28 22:37:33 UTC.- Displayed in
Data interval startfield
- Displayed in
Data interval end: 2022-08-28 22:42:33 UTC.- 5 minutes later
Logical date of Next DAG run: 2022-08-28 22:42:33 UTC.- Displayed in
Next Runfield - 5 minutes after the previous logical date
- Same as
Data interval endof previous DAG run

- Displayed in
Run After: 2022-08-28 22:47:33 UTC.- You can see if you hover over
Next Run. - The date and time that the next DAG run will actually start
- The same as the value in the
Data intervalend for the next DAG run.
- You can see if you hover over
The following is a comparison of the two successive DAG runs:
- DAG run 1 (
scheduled__2022-08-28T22:37:33.620191+00:00) has a logical date of2022-08-28 22:37:33, a data interval start of2022-08-28 22:37:33and a data interval end of2022-08-28 22:42:33. This DAG run will actually start at2022-08-28 22:42:33. - DAG run 2 (
scheduled__2022-08-28T22:42:33.617231+00:00) has a logical date of2022-08-28 22:42:33, a data interval start of2022-08-28 22:42:33and a data interval end of2022-08-28 22:47:33. This DAG run will actually start at2022-08-28 22:47:33.
Why Airflow starts after the data interval?
Airflow was originally developed for extract, transform, and load (ETL) operations with the expectation that data is constantly flowing in from some source and then will be summarized at a regular interval. However, if you want to summarize data from Monday, you need to wait until Tuesday at 12:01 AM. This shortcoming led to the introduction of timetables in Airflow 2.2+. This is an advanced level of scheduling in Airflow and we will not cover it.
For pipelines with straightforward scheduling needs, you can define a schedule (or schedule_interval) in your DAG using:
- A cron expression.
- We set time interval.
- For example, if you want to schedule your DAG at
4:05 AM every day, you would use schedule=‘5 4 * * *’.
- A cron preset.
- For example, schedule=’@hourly’ will schedule the DAG to run at the beginning of every hour.
- A
timedeltaobject.- If you want to schedule your DAG on a particular rhythm (hourly, every 5 minutes, etc.) rather than at a specific time, you can pass a
timedeltaobject imported from thedatetimepackage to thescheduleparameter. - Here we set time duration and not time interval.
- For example,
schedule=timedelta(minutes=30)will run the DAG every thirty minutes, andschedule=timedelta(days=1)will run the DAG every day.
- If you want to schedule your DAG on a particular rhythm (hourly, every 5 minutes, etc.) rather than at a specific time, you can pass a
If your DAG does not need to run on a schedule and will only be triggered manually or externally triggered by another process, you can set schedule=None.
DAG should run idempotent (able to be re-run without changing the results), so do not use datetime.now() for scheduling.
Cron Expressions [Extra section]
-
cronis a basic utility available on Unix-based systems. It enables users to schedule tasks to run periodically at a specified date/time. -
Cron runs as a daemon process. This means it only needs to be started once and it will keep running in the background.
-
A cron schedule is a simple text file located under
/var/spool/cron/crontabson Linux systems. We cannot edit the crontab files directly, so we need to access it using thecrontabcommand. To open crontab file, we need to run the following command:crontab -e -
Each line in crontab is an entry with an expression and a command to run:
* * * * * echo hello_cron >> ~/cron_hello.txt -
The cron expression consists of five fields:
<minute> <hour> <day-of-month> <month> <day-of-week> <command>
The range of each field is: <minute> (0-59), <hour> (0-23), <day-of-month> (1-31), <month> (1-12), <day-of-week> (0-6).
- Special Characters in Expression
*(all) specifies that event should happen for every time unit. For example,*in the <minute> field means “for every minute”.?(any) is utilized in the <day-of-month> and <day-of -week> fields to denote the arbitrary value and thus neglect the field value. For example, if we want to run a script at “5th of every month” irrespective of what day of the week falls on that date, we specify a “?” in the <day-of-week> field.-(range) determines the value range. For example, “10-11” in the <hour> field means “10th and 11th hours”.,(values) specifies multiple values. For example, “MON, WED, FRI” in <day-of-week> field means on the days “Monday, Wednesday and Friday”./(increments) specifies the incremental values. For example, a “5/15” in the <minute> field means at “5, 20, 35 and 50 minutes of an hour”.
Cron expressions are historically used to schedule tasks in Apache Airflow.
You can use the website https://crontab.guru/ to check your cron expressions.
Airflow DAG APIs
Apache Airflow provides two APIs for creating DAGs. The legacy API uses operators (airflow.operators) and DAG (airflow.DAG) objects without using decorators. TaskFlow API (airflow.decorators) is the new recommended way to create dags where dags and tasks are written using decorators (@dag and @task).
We can mix those APIs in the same DAG. For instance, you can use TaskFlow API for creating one of the tasks and the traditional API for another task defined both in a DAG which is created using the traditional/new API.
For example, the Hello World Workflow is a DAG created using the traditional API, where the first task is created using traditional API and the second task is created using TaskFlow API.
DAG definition files are python files (.py) but should be stored in a location where Airflow can see it. This location can be determined in airflow.cfg as follows:
# line 7
dags_folder = /home/firasj/project/services/airflow/dags
Steps need to be considered when building a pipeline and writing its DAG definition file:
- Declare the DAG function with required parameters.
- Declare the task functions with required parameters.
- Call the task functions inside the DAG.
- Specify the dependency between the tasks.
- Call the DAG function.
- Check that you set a
scheduleandstart_datefor the DAG. - Check that you set
dag_idfor the dag andtask_idfor each task. - Check if you want
catchupfor past DAG runs. - Go to Airflow web UI to track the workflow/DAG and check if there are import errors.
DAG Examples
We have three common ways to write DAG definition files in Airflow. We can define the DAG using:
1. Traditional API as a variable
# pipelines/hello_dag1.py
from pendulum import datetime
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperator
# A DAG represents a workflow, a collection of tasks
# It is a variable
dag = DAG(dag_id="hello_dag1",
start_date=datetime(2022, 1, 1, tz="UTC"),
schedule=None,
catchup=False)
# Tasks here are created via instantating operators
# You need to pass the dag for all tasks
# Bash task
hello = BashOperator(task_id="hello1",
bash_command="echo hello ",
dag = dag)
def msg():
print("airflow!")
# Python task
msg = PythonOperator(task_id="msg1",
python_callable=msg,
dag=dag)
# Set dependencies between tasks
hello >> msg
2. Traditional API as a context
# pipelines/hello_dag2.py
from pendulum import datetime
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperator
# A DAG represents a workflow, a collection of tasks
# DAG is defined as a context
with DAG(dag_id="hello_dag2",
start_date=datetime(2022, 1, 1, tz="UTC"),
schedule=None,
catchup=False) as dag:
# WE do NOT pass dag here
hello = BashOperator(task_id="hello2",
bash_command="echo hello ")
def msg():
print("airflow!")
called_msg = PythonOperator(task_id="msg2",
python_callable=msg)
# Set dependencies between tasks
# hello >> msg
hello.set_downstream(called_msg)
# OR
# msg.set_upstream(hello)
3. TaskFlow API
# pipelines/hello_dag3.py
from pendulum import datetime
from airflow.decorators import dag, task
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperator
from airflow.models.baseoperator import chain
@dag(
dag_id="hello_dag3",
start_date=datetime(2022, 1, 1, tz="UTC"),
schedule=None,
catchup=False
)
def print_hello():
# Tasks here are created via instantating operators
# Bash task is defined using Traditional API
# There is a decorator @task.bash in Airflow 2.9+ as a replacement for this
hello = BashOperator(task_id="hello3", bash_command="echo hello ")
# Python task is defined sing TaskFlow API
@task(
task_id = "msg31"
)
def msg():
"""Prints a message"""
print("airflow!")
called_msg = PythonOperator(task_id="msg32", python_callable=msg)
# Set dependencies between tasks
# hello >> msg
# OR
# hello.set_downstream(msg)
# OR
# msg.set_upstream(hello)
# OR
chain(hello, msg)
# Call the pipeline since it is defined as a function
print_hello()
Note on bash_command in BashOperator: Add a space after the script name when directly calling a .sh script with the bash_command argument – for example bash_command="my_script.sh ". This is because Airflow tries to load this file and process it as a Jinja template. Example is here.
P.S. Jinja templating is web template engine and lets you define your own variables inside of a template with the {% set %} block such that you can set them at runtime in a dynamic manner. Jinja Syntax:
{{ ... }} : delimiter for variables or expressions
{% ... %} : delimiter for statements such as if or for
{# ... #} : comment

Templates reference in Airflow is here.
Xcoms [extra section]
# pipelines/example_xcoms_vars_dag.py
import pendulum
from airflow.decorators import task
from airflow.models.dag import DAG
from airflow.models.xcom_arg import XComArg
from airflow.operators.bash import BashOperator
value_1 = [1, 2, 3]
value_2 = {"a": "b"}
@task
def push(ti=None):
"""Pushes an XCom without a specific target"""
ti.xcom_push(key="value from pusher 1", value=value_1)
@task
def push_by_returning():
"""Pushes an XCom without a specific target, just by returning it"""
return value_2
def _compare_values(pulled_value, check_value):
if pulled_value != check_value:
raise ValueError(f"The two values differ {pulled_value} and {check_value}")
@task
def puller(pulled_value_2, ti=None):
"""Pull all previously pushed XComs and check if the pushed values match the pulled values."""
pulled_value_1 = ti.xcom_pull(task_ids="push", key="value from pusher 1")
_compare_values(pulled_value_1, value_1)
_compare_values(pulled_value_2, value_2)
@task
def pull_value_from_bash_push(ti=None):
bash_pushed_via_return_value = ti.xcom_pull(key="return_value", task_ids="bash_push")
bash_manually_pushed_value = ti.xcom_pull(key="manually_pushed_value", task_ids="bash_push")
print(f"The xcom value pushed by task push via return value is {bash_pushed_via_return_value}")
print(f"The xcom value pushed by task push manually is {bash_manually_pushed_value}")
with DAG(
"example_xcom",
schedule="@once",
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
tags=["example"],
) as dag:
bash_push = BashOperator(
task_id="bash_push",
bash_command='echo "bash_push demo" && '
'echo "Manually set xcom value '
'{{ ti.xcom_push(key="manually_pushed_value", value="manually_pushed_value") }}" && '
'echo "value_by_return"',
)
bash_pull = BashOperator(
task_id="bash_pull",
bash_command='echo "bash pull demo" && '
f'echo "The xcom pushed manually is {XComArg(bash_push, key="manually_pushed_value")}" && '
f'echo "The returned_value xcom is {XComArg(bash_push)}" && '
'echo "finished"',
do_xcom_push=False,
)
python_pull_from_bash = pull_value_from_bash_push()
[bash_pull, python_pull_from_bash] << bash_push
puller(push_by_returning()) << push()
Python tasks with virtual environments
# pipelines/example_python_task_venv_dag.py
"""
Example DAG demonstrating the usage of the TaskFlow API to execute Python functions natively and within a virtual environment.
"""
import sys
import time
import pendulum
from airflow.decorators import dag, task
from airflow.operators.python import is_venv_installed
PATH_TO_PYTHON_BINARY = sys.executable
@dag(
dag_id="example_python_venv",
schedule=None,
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
tags=["example"],
)
def example_python_decorator():
# Generate 5 sleeping tasks, sleeping from 0.0 to 0.4 seconds respectively
@task
def my_sleeping_function(random_base):
"""This is a function that will run within the DAG execution"""
time.sleep(random_base)
for i in range(5):
sleeping_task = my_sleeping_function.override(task_id=f"sleep_for_{i}")(random_base=i / 10)
if not is_venv_installed():
print("The virtalenv_python example task requires virtualenv, please install it.")
else:
@task.virtualenv(
task_id="virtualenv_python", requirements=["colorama==0.4.0"], system_site_packages=False
)
def callable_virtualenv():
"""
Example function that will be performed in a virtual environment.
Importing at the module level ensures that it will not attempt to import the
library before it is installed.
"""
from time import sleep
from colorama import Back, Fore, Style
print(Fore.RED + "some red text")
print(Back.GREEN + "and with a green background")
print(Style.DIM + "and in dim text")
print(Style.RESET_ALL)
for _ in range(4):
print(Style.DIM + "Please wait...", flush=True)
sleep(1)
print("Finished")
virtualenv_task = callable_virtualenv()
sleeping_task >> virtualenv_task
@task.external_python(task_id="external_python", python=PATH_TO_PYTHON_BINARY)
def callable_external_python():
"""
Example function that will be performed in a virtual environment.
Importing at the module level ensures that it will not attempt to import the
library before it is installed.
"""
import sys
from time import sleep
print(f"Running task via {sys.executable}")
print("Sleeping")
for _ in range(4):
print("Please wait...", flush=True)
sleep(1)
print("Finished")
external_python_task = callable_external_python()
external_python_task >> virtualenv_task
dag = example_python_decorator()
# Test the pipeline by running
# python pipelines/example_python_task_venv_dag.py
if __name__=="__main__":
dag.test()
ExternalTaskSensor
# pipelines/example_external_task_sensor_dag.py
import pendulum
from airflow.models.dag import DAG
from airflow.operators.empty import EmptyOperator
from airflow.operators.bash import BashOperator
from airflow.sensors.external_task import ExternalTaskMarker, ExternalTaskSensor
from datetime import timedelta
from airflow.decorators import task
start_date = pendulum.datetime(2024, 6, 27, 19, 30, tz = "Europe/Moscow")
with DAG(
dag_id="example_external_task_sensor_parent",
start_date=start_date,
catchup=False,
schedule=timedelta(minutes=1),
tags=["example2"],
) as parent_dag:
parent_task = BashOperator(
task_id = "parent_task",
bash_command="echo Run this before! ",
cwd="/"
)
with DAG(
dag_id="example_external_task_sensor_child",
start_date=start_date,
schedule=timedelta(minutes=1),
catchup=False,
tags=["example2"],
) as child_dag:
child_task1 = ExternalTaskSensor(
task_id="child_task1",
external_dag_id=parent_dag.dag_id,
external_task_id=parent_task.task_id,
timeout=600
)
@task(task_id = "child_task2")
def run_this_after():
print("I am running!")
child_task2 = run_this_after()
child_task1 >> child_task2
Trigger Dag Run operator
It triggers a DAG run for a specified dag_id.
# pipelines/example_trigger_controller_dag.py
import pendulum
from airflow.models.dag import DAG
from airflow.operators.trigger_dagrun import TriggerDagRunOperator
with DAG(
dag_id="example_trigger_controller_dag",
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
schedule="@once",
tags=["example"],
) as dag:
trigger = TriggerDagRunOperator(
task_id="test_trigger_dagrun",
# Ensure this equals the dag_id of the DAG to trigger
trigger_dag_id="example_trigger_target_dag",
)
# pipelines/example_trigger_target_dag.py
import pendulum
from airflow.decorators import task
from airflow.models.dag import DAG
from airflow.operators.bash import BashOperator
@task(task_id="run_this")
def run_this_func(dag_run=None):
"""
Print the payload "message" passed to the DagRun conf attribute.
:param dag_run: The DagRun object
"""
print("triggerred task!")
with DAG(
dag_id="example_trigger_target_dag",
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
schedule=None,
tags=["example"],
) as dag:
run_this = run_this_func()
bash_task = BashOperator(
task_id="bash_task",
bash_command='sleep 60 && echo "Run this after the target"'
)
Info: You can check more DAG examples from here.
Deferrable operators [Extra section]
- They use the Python
asynciolibrary to run tasks waiting for an external resource to finish (asynchronous run). - This frees up your workers and allows you to use resources more effectively.
- Triggers: Small, asynchronous sections of Python code. Due to their asynchronous nature, they coexist efficiently in a single process known as the triggerer which runs an asyncio event loop in your Airflow environment.
- Running a triggerer is essential for using deferrable operators.
- For example, the
DateTimeSensorAsyncwaits asynchronously for a specific date and time to occur. - Note that your Airflow environment needs to run a triggerer component to use deferrable operators.
- Deferred task: An Airflow task state indicating that a task has paused its execution, released the worker slot, and submitted a trigger to be picked up by the triggerer process.
- With traditional operators, worker slots are occupied, tasks are queued and start times are delayed.

- With deferrable operators, worker slots are released when a task is polling for the job status. When the task is deferred, the polling process is offloaded as a trigger to the triggerer, and the worker slot becomes available. The triggerer can run many asynchronous polling tasks concurrently, and this prevents polling tasks from occupying your worker resources. When the terminal status for the job is received, the task resumes, taking a worker slot while it finishes. The following image illustrates this process:

- Deferrable operators should be used whenever you have tasks that occupy a worker slot while polling for a condition in an external system. For example, using deferrable operators for sensor tasks can provide efficiency gains and reduce operational costs.
- Many Airflow operators, such as the
TriggerDagRunOperator, can be set to run in deferrable mode using thedeferrableparameter.
Example
The following example DAG is scheduled to run every minute between its start_date and its end_date. Every DAG run contains one sensor task that will potentially take up to 20 minutes to complete.
from airflow.decorators import dag
from airflow.sensors.date_time import DateTimeSensor
from pendulum import datetime
@dag(
start_date=datetime(2024, 5, 23, 20, 0),
end_date=datetime(2024, 5, 23, 20, 19),
schedule="* * * * *",
catchup=True,
)
def sync_dag_2():
DateTimeSensor(
task_id="sync_task",
target_time="""{{ macros.datetime.utcnow() + macros.timedelta(minutes=20) }}""",
)
sync_dag_2()
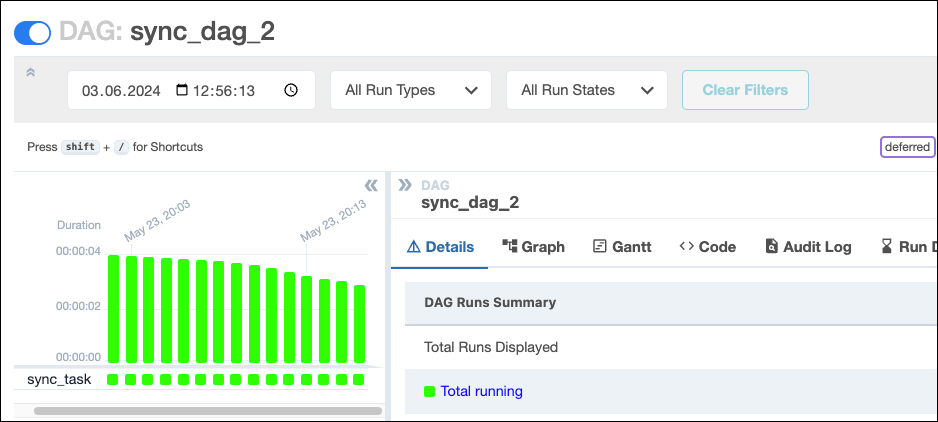
Note: Using DateTimeSensor, one worker slot is taken up by every sensor that runs.
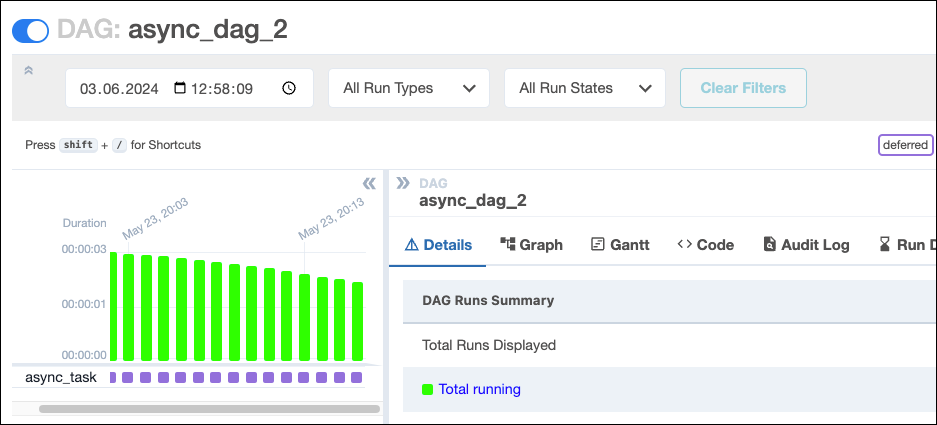
By using the deferrable version of this sensor, DateTimeSensorAsync, you can achieve full concurrency while freeing up your workers to complete additional tasks across your Airflow environment.
from airflow.decorators import dag
from pendulum import datetime
from airflow.sensors.date_time import DateTimeSensorAsync
@dag(
start_date=datetime(2024, 5, 23, 20, 0),
end_date=datetime(2024, 5, 23, 20, 19),
schedule="* * * * *",
catchup=True,
)
def async_dag_2():
DateTimeSensorAsync(
task_id="async_task",
target_time="""{{ macros.datetime.utcnow() + macros.timedelta(minutes=20) }}""",
)
async_dag_2()
In the previous screenshot, all tasks are shown in a deferred (violet) state. Tasks in other DAGs can use the available worker slots, making the deferrable operator more cost and time-efficient.
Test a pipeline
- You can test a pipeline from airflow CLI as follows:
airflow dags test <dag-id>
This will run the dag only for one time. This is not scheduling dags.
- You can also test it in VS code by adding the code snippet below to the end of the dag definition file:
if __name__ == "__main__":
dag.test()
# dag is an instance of DAG
Airflow UI
The Airflow UI makes it easy to monitor and troubleshoot your data pipelines. Here’s a quick overview of some of the features and visualizations you can find in the Airflow UI.
DAGs View
List of the DAGs in your environment, and a set of shortcuts to useful pages. You can see exactly how many tasks succeeded, failed, or are currently running at a glance.
Cluster Activity View
Native Airflow dashboard page into the UI to collect several useful metrics for monitoring your Airflow cluster.
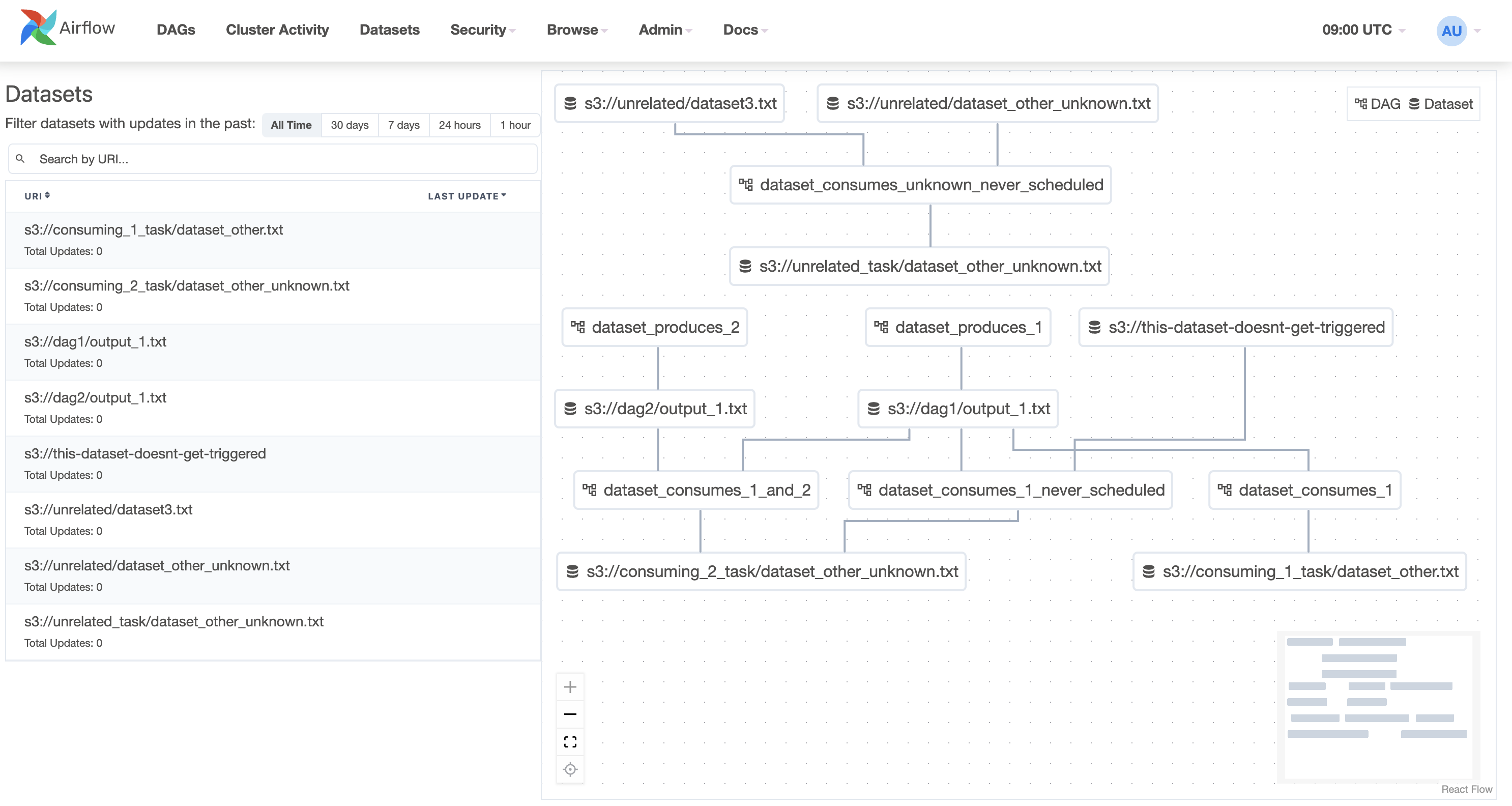
Datasets View
A combined listing of the current datasets and a graph illustrating how they are produced and consumed by DAGs.
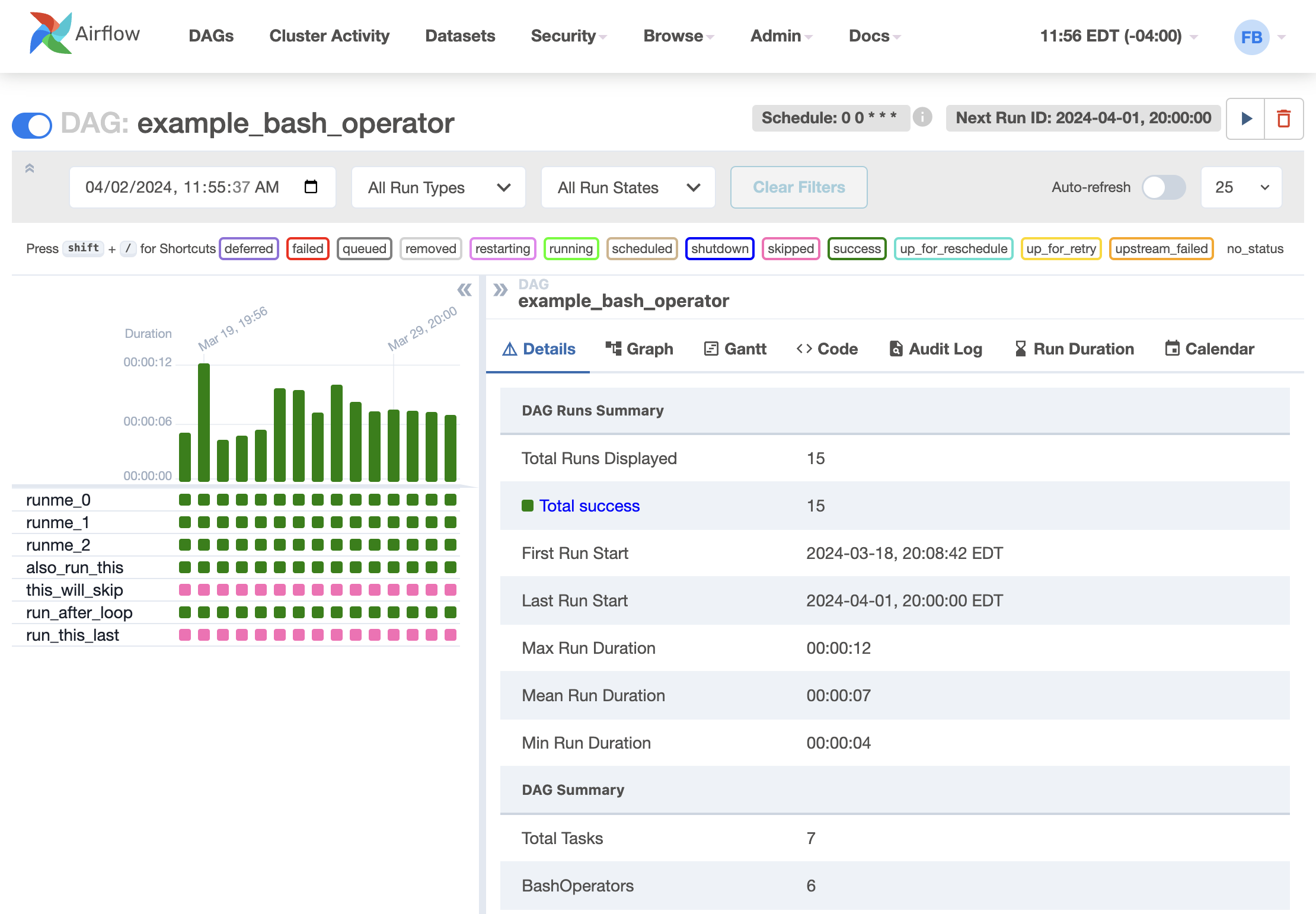
Grid View
A bar chart and grid representation of the DAG that spans across time. The top row is a chart of DAG Runs by duration, and below, task instances. If a pipeline is late, you can quickly see where the different steps are and identify the blocking ones.
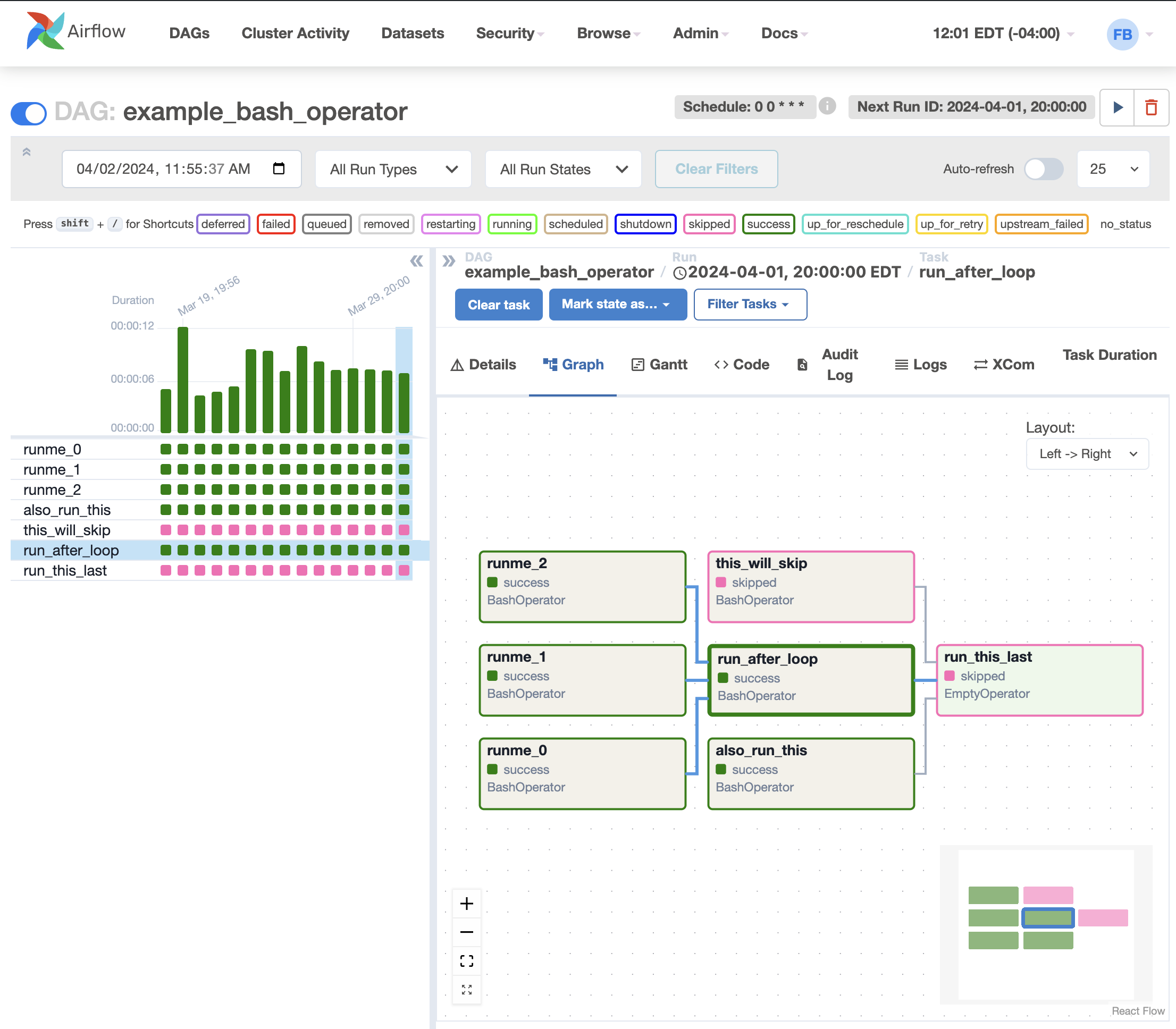
Graph View
The graph view is perhaps the most comprehensive. Visualize your DAG’s dependencies and their current status for a specific run.
The landing time for a task instance is the delta between the dag run’s data interval end (typically this means when the dag “should” run) and the dag run completion time.
ZenML
ZenML is an extensible, open-source MLOps framework for creating portable, production-ready machine learning pipelines.
# You do not need to run this if you installed the package from requirements.txt
pip install zenml[server]
This will install ZenML with with the dashboard.
Note that ZenML currently supports Python 3.8, 3.9, 3.10, and 3.11. Please make sure that you are using a supported Python version.
Important notes:
- Before running ZenML pipelines or deploying ZenML stack. We need to customize the ZenML config folder as follows.
# PWD is project folder export ZENML_CONFIG_PATH=$PWD/services/zenml - Make sure that you set this environment variable before you work with ZenML. This will store the configs and metadata in the specified folder. This folder needs to be pushed to Github.
- You can add this to your
~/.bashrcfile as a permanent variable but replace$PWDwith your absolute project path.# REPLACE <project-folder-path> with your project folder path cd <project-folder-path> echo "export ZENML_CONFIG_PATH=$PWD/services/zenml" >> ~/.bashrc # Run the file source ~/.bashrc # Activate the virtual environment again source .venv/bin/activate
Core concepts
Step
Steps are functions annotated with the @step decorator. They represent a single stage to be used in a pipeline.
@step
def step_1() -> str:
"""Returns a string."""
return "world"
These “step” functions can also have inputs and outputs. For ZenML to work properly, these should preferably be typed.
@step(enable_cache=False)
def step_2(input_data: str, input_data2: str) -> str:
"""Combines the two strings passed in."""
output = f"{input_data} {input_data2}"
return output # Output
Pipelines
At its core, ZenML follows a pipeline-based workflow for your projects. A pipeline consists of a series of steps, organized in any order that makes sense for your use case. Pipelines are simple Python functions decorated with @pipeline. It is only allowed to call steps within this function.
@pipeline
def my_pipeline():
output_step_one = step_1()
step_2(input_data="hello", input_data2=output_step_one)
The inputs for steps called within a pipeline can either be the outputs of previous steps or alternatively, you can pass in values directly (as long as they’re JSON-serializable).
Executing the Pipeline is as easy as calling the function that you decorated with the @pipeline decorator.
if __name__=="__main__":
my_pipeline()
Artifacts
Artifacts represent the data that goes through your steps as inputs and outputs and they are automatically tracked and stored by ZenML in the artifact store.
Materializers
A ZenML pipeline is built in a data-centric way. The outputs and inputs of steps define how steps are connected and the order in which they are executed. Each step should be considered as its very own process that reads and writes its inputs and outputs from and to the artifact store.
A materializer dictates how a given artifact can be written to and retrieved from the artifact store and also contains all serialization and deserialization logic. Whenever you pass artifacts as outputs from one pipeline step to other steps as inputs, the corresponding materializer for the respective data type defines how this artifact is first serialized and written to the artifact store, and then deserialized and read in the next step.
Check this page for more info.
ZenML Example
Here we will build an ETL pipeline to extract the data from the datastore, transform it, validate it, then load it to the feature store.
ETL data pipeline
This pipeline is a typical example of one of the pipelines required for the project. As you can see, you have to write the boilerplate code in src folder/package and here you just call them. Notice the input and output for each step. All the input and ouptut in this pipeline are materialized and versioned in an artifact store (SQLite db file locally).
You should work on building data pipelines using ZenML and Airflow for the project, as follows:
- Determine the steps of the pipeline.
- Specify the input/output for each step.
- For each step, write a function in
src/data.pyto perform a single step of the pipeline. - Add test function in
testsfolder to test each function you added insrc/data.py. Test the functions. - Call/Use the functions from
src/data.pyin the steps of the pipeline. - Create and call the pipeline.
- Run the pipeline using
zenml.python pipelines/<file.py>
- Schedule and orchestrate the pipeline using
Apache Airflow.- You can create a Bash operator for running the previous command.
# pipelines/data_prepare.py
import pandas as pd
from typing_extensions import Tuple, Annotated
from zenml import step, pipeline, ArtifactConfig
from data import transform_data, extract_data, load_features, validate_transformed_data
from utils import get_sample_version
import os
BASE_PATH = os.path.expandvars("$PROJECTPATH")
@step(enable_cache=False)
def extract()-> Tuple[
Annotated[pd.DataFrame,
ArtifactConfig(name="extracted_data",
tags=["data_preparation"]
)
],
Annotated[str,
ArtifactConfig(name="data_version",
tags=["data_preparation"])]
]:
df, version = extract_data(BASE_PATH)
return df, version
@step(enable_cache=False)
def transform(df: pd.DataFrame)-> Tuple[
Annotated[pd.DataFrame,
ArtifactConfig(name="input_features",
tags=["data_preparation"])],
Annotated[pd.DataFrame,
ArtifactConfig(name="input_target",
tags=["data_preparation"])]
]:
# Your data transformation code
X, y = transform_data(df)
return X, y
@step(enable_cache=False)
def validate(X:pd.DataFrame,
y:pd.DataFrame)->Tuple[
Annotated[pd.DataFrame,
ArtifactConfig(name="valid_input_features",
tags=["data_preparation"])],
Annotated[pd.DataFrame,
ArtifactConfig(name="valid_target",
tags=["data_preparation"])]
]:
X, y = validate_transformed_data(X, y)
return X, y
@step(enable_cache=False)
def load(X:pd.DataFrame, y:pd.DataFrame, version: str)-> Tuple[
Annotated[pd.DataFrame,
ArtifactConfig(name="features",
tags=["data_preparation"])],
Annotated[pd.DataFrame,
ArtifactConfig(name="target",
tags=["data_preparation"])]
]:
load_features(X, y, version)
return X, y
@pipeline()
def prepare_data_pipeline():
df, version = extract()
X, y = transform(df)
X, y = validate(X, y)
X, y = load(X, y, version)
if __name__=="__main__":
run = prepare_data_pipeline()
You can run the pipeline as:
python pipelines/data_prepare.py
OR more specific about pipeline selection:
python pipelines/data_prepare.py -prepare_data_pipeline
DEclaring the data types for the input and output of the step functions is important as it determines how the artifact will be materialized and saved in the artifact store.
Explore ZenML Dashboard
Once the pipeline has finished its execution, use the zenml up command to view the results in the ZenML Dashboard. Using that command will open up the browser automatically.
# Make sure that you customized the config folder for ZenML
zenml up
Usually, the dashboard is accessible at (http://127.0.0.1:8237/). Log in with the default username “default” (password not required) and see your recently pipeline run.

If you have closed the browser tab with the ZenML dashboard, you can always reopen it by running the following command in your terminal.
zenml show
ZenML Stacks
A stack is the configuration of tools and infrastructure that your pipelines can run on. When you run ZenML code without configuring a stack, the pipeline will run on the so-called default stack.

We can see the separation of code from configuration and infrastructure. A stack consists of multiple components. All stacks have at minimum an orchestrator and an artifact store.
- Describe ZenML stack
zenml stack describe
- List all stacks
zenml stack list
Orchestrator
The orchestrator is responsible for executing the pipeline code. In the simplest case, this will be a simple Python thread on your machine. Let’s explore this default orchestrator.
- To list all orchestrators that are registered in your zenml deployment.
zenml orchestrator list
Artifact store
The artifact store is responsible for persisting the step outputs.
- List the artifact stores
zenml artifact-store list
- List all flavors of artifact stores
zenml artifact-store flavor --list
You can use ZenML API to get a specific version of the artifact:
from zenml.client import Client
client = Client()
# data: pd.DataFrame (Materialized data)
data = client.get_artifact_version(name_id_or_prefix="initial_dataframe", version=4).load()
# This will retrieve the version 4 of the artifact named `initial_dataframe`. This name is the same when we defined annotated output for the first step of the previous data pipeline.
print(data.shape)
Register a new artifact store [extra section]
You can create a new artifact store by running the following command:
zenml artifact-store register my_artifact_store --flavor=local
You can describe your new artifact store as follows:
zenml artifact-store describe my_artifact_store
Artifact store API
When calling the Artifact Store API, you should always use URIs that are relative to the Artifact Store root path.
import os
from zenml.client import Client
from zenml.io import fileio
# Artifact Store root path
root_path = Client().active_stack.artifact_store.path
# create a custom artifact and store in artifact store
artifact_contents = "example artifact"
artifact_path = os.path.join(root_path, "artifacts", "examples")
artifact_uri = os.path.join(artifact_path, "test.txt")
fileio.makedirs(artifact_path)
with fileio.open(artifact_uri, "w") as f:
f.write(artifact_contents)
Create a local stack [extra section]
With the artifact store created, we can now create a new stack with this artifact store.
zenml stack register my_local_stack -o default -a my_artifact_store
To run a pipeline using the new stack:
- set the stack as active on your client
zenml stack set my_local_stack
- Run your pipeline code
# Initiates a new run for the pipeline: prepare_data_pipeline
python pipelines/prepare_data_pipeline.py -prepare_data_pipeline
Manage artifacts in ZenML
ZenML takes a proactive approach to data versioning, ensuring that every artifact—be it data, models, or evaluations—is automatically tracked and versioned upon pipeline execution.
Adding artifacts
ZenML automatically versions all created artifacts using auto-incremented numbering. Yo can use ArtifactConfig to add version and metadata to the artifacts.
from zenml import step, get_step_context, ArtifactConfig
from typing_extensions import Annotated
# below we combine both approaches, so the artifact will get
# metadata and tags from both sources
@step
def training_data_loader() -> (
Annotated[
str,
ArtifactConfig(
name="artifact_name",
version="version_number",
run_metadata={"metadata_key": "metadata_value"},
tags=["tag_name"],
),
]
):
step_context = get_step_context()
step_context.add_output_metadata(
output_name="artifact_name", metadata={"metadata_key2": "metadata_value2"}
)
step_context.add_output_tags(output_name="artifact_name", tags=["tag_name2"])
return "string"
- List the artifacts
zenml artifact list
- List the artifact version
zenml artifact version list
- List ther artifact version of a spcific artifact “valid_input_dataframe”
zenml artifact version list --name valid_input_dataframe
Consuming artifacts
Within the pipeline
from uuid import UUID
import pandas as pd
from zenml import step, pipeline
from zenml.client import Client
@step
def process_data(dataset: pd.DataFrame):
...
@pipeline
def training_pipeline():
client = Client()
# Fetch by ID
dataset_artifact = client.get_artifact_version(
name_id_or_prefix=UUID("3a92ae32-a764-4420-98ba-07da8f742b76")
)
# Fetch by name alone - uses the latest version of this artifact
dataset_artifact = client.get_artifact_version(name_id_or_prefix="iris_dataset")
# Fetch by name and version
dataset_artifact = client.get_artifact_version(
name_id_or_prefix="iris_dataset", version="raw_2023"
)
# Pass into any step
process_data(dataset=dataset_artifact)
if __name__ == "__main__":
training_pipeline()
Outside the pipeline
import numpy as np
from zenml import ExternalArtifact, pipeline, step, save_artifact, load_artifact
def f(df):
save_artifact(df, name="df_dataframe")
@step
def print_data(data: np.ndarray):
print(data)
@pipeline
def printing_pipeline():
# One can also pass data directly into the ExternalArtifact
# to create a new artifact on the fly
data = ExternalArtifact(value=np.array([0]))
print_data(data=data)
load_artifact(name="df_dataframe")
if __name__ == "__main__":
printing_pipeline()
Schedule ZenML pipelines using Airflow
We can run the ZenML pipelines (pipelines/data_prepare.py) by simply running it as follows:
python pipelines/prepare_data_pipeline.py -prepare_data_pipeline
We can consider this as a bash command and use BashOperator or @task.bash to run the pipeline as follows:
...
# REPLACE <project-folder-path>
zenml_pipeline = BashOperator(
task_id="run_zenml_pipeline",
bash_command="python <project-folder-path>/services/airflow/dags/data_prepare.py -prepare_data_pipeline ",
cwd="<project-folder-path>/project", # specifies the current working directory
)
...
Do not run the ZenML pipeline by simply calling the pipeline function using a PythonOperator.
Feast [Extra section]
Feast is a standalone, open-source feature store that organizations use to store and serve features consistently for offline training and online inference. Feast allows to:
- Make features consistently available for training and serving by managing an offline store (to process historical data for scale-out batch scoring or model training), a low-latency online store (to power real-time prediction), and a battle-tested feature server (to serve pre-computed features online).
- Avoid data leakage by generating point-in-time correct feature sets so data scientists can focus on feature engineering rather than debugging error-prone dataset joining logic. This ensure that future feature values do not leak to models during training.
- Decouple ML from data infrastructure by providing a single data access layer that abstracts feature storage from feature retrieval, ensuring models remain portable as you move from training models to serving models.

Note: Feast today primarily addresses timestamped structured data.
Note: If your data in the dataframe does not have timestamps, you need to create dummy timestamps and add them to the dataframe in order to persist it in the feature store.
Core concepts
The top-level namespace within Feast is a project. Users define one or more feature views within a project. Each feature view contains one or more features. These features typically relate to one or more entities. A feature view must always have a data source, which in turn is used during the generation of training datasets and when materializing feature values into the online store.

Install feast
# You do not need to run this if you installed the package from requirements.txt
pip install feast
Note: feast 0.36.0+ may work with Windows but it has conflicts with other packages in our toolset. The earlier versions of feast usually do not work on Windows. If you try to run, you may see such errors fcntl module not found. Windows users are working on Ubuntu WSL2 and no issues will be encountered I presume.
Demo
Here we will build a local feature store to store the ML-ready dataset.
1. Create a feature repository
# Create a directory for feast metadata
mkdir -p services/feast
# Access the folder
# cd services/feast
# feast_project should be a name and they do not support path
feast -c services/feast init -t local -m feast_project
# Access the feast repo
cd feast_project/feature_repo
The repo has feature_store.yaml which contains a demo setup configuring where data sources are.
2. Configure the feature repository
The configuration of the feature repository is in the location services\feast\feast_project\feature_repo\feature_store.yaml. We can configure it as follows:
project: feast_project
registry: registry.db
provider: local
online_store:
type: sqlite
path: online_store.db
offline_store:
type: file
entity_key_serialization_version: 2
The following top-level configuration options exist in the feature_store.yaml file.
- provider — Configures the environment in which Feast will deploy and operate.
- registry — Configures the location of the feature registry.
- online_store — Configures the online store.
- offline_store — Configures the offline store.
- project — Defines a namespace for the entire feature store. Can be used to isolate multiple deployments in a single installation of Feast. Should only contain letters, numbers, and underscores.
3. Run sample workflow
- Prepare your data for loading to the feature store.
# Add two columns
# The timestamp and an id to reconize each row in the dataframe
- Persist features to offline store
from feast import (
Entity,
FeatureView,
FileSource,
ValueType,
FeatureService
)
from feast.types import Int32, Float32
import os
from utils import init_hydra
BASE_PATH = os.path.expandvars("$PROJECTPATH")
cfg = init_hydra()
PATH = cfg.features_path
entity_df = Entity(
name="bank_data",
value_type=ValueType.INT32,
description="Identifier",
join_keys=['id']
)
source = FileSource(
name="bank_data_source",
path = PATH,
timestamp_field="timestamp"
)
view = FeatureView(
name = "bank_data_feature_views",
entities=[entity_df],
source=source,
online=False,
tags={},
# schema=
)
# This groups features into a feature service
# We will use it for versioning
bank_records = FeatureService(
name="bank_data_features" + "_" + cfg.features_version,
features=[
view
],
)
- Retrieve features from offline store
# services/feast/feast_repo/feature_repo/feast_repo.py
from utils import init_hydra
cfg = init_hydra()
REPO_PATH = cfg.feature_store_path
store = FeatureStore(repo_path=REPO_PATH)
entity_df = Entity(
name="bank_data",
value_type=ValueType.INT32,
description="Identifier",
join_keys=['id']
)
training_df = store.get_historical_features(
entity_df=entity_df,
).to_df()
print("----- Feature schema -----\n")
print(training_df.info())
print()
print("----- Example features -----\n")
print(training_df.head())
- Register feature definitions and deploy your feature store
# services/feast/feast_repo/feature_repo/test_workflow.py
# Make sure that you access the feature repo folder
# cd services/feast/feast_project/feature_repo/
# feast apply
# OR
feast -c services/feast/feast_project/feature_repo apply
4. Browse your features with the Feast Web UI
You can access the Feast Web UI via running the following command:
feast -c services/feast/feast_project/feature_repo ui

The server by default runs on port 8888.
Project tasks
Note: The project tasks are graded, and they form the practice part of the course. We have tasks for repository and as well as for report (for Master’s student).
A. Repository
- Build an automated workflow (
pipelines/data_extract_dag.py) in Apache Airflow to perform the following 4 tasks. The workflow should be scheduled to run every 5 minutes (increase the time if your DAG run takes more than 5 minutes). This pipeline should be atomic such that if a single task/step fails, then all of the tasks/steps fail (default case in Apache Airflow).- Extract a new sample of the data.
- You can use the functions you defined in phase 1.
- Validate the sample using Great Expectations.
- You can use the functions you defined in phase 1.
- Version the sample using dvc.
- You can use the scripts you defined in phase 1.
- keep the version number of this data in a file
./configs/data_version.yaml.
- Load the sample to the data store (remote storage of dvc repository in the local filesystem).
- You can use the scripts you defined in phase 1.
- Extract a new sample of the data.
- Build an ETL pipeline (
pipelines/data_prepare.py) using ZenML. The data pipeline consists of 4 tasks as follows:- Extract the data sample from the data store.
- Write a function
read_datastoreinsrc/data.pywhich returns the sample as a dataframe/tensor. - Get the version number of this data from a file
./configs/data_version.yaml. - Send to the next step, the dataframe and data version.
- Write a function
- Transform the data sample into features.
- Write a function
preprocess_datainsrc/data.pywhich transforms the input data sample into features and returns them as a dataframe/tensor. - Send to the next step, the dataframe (X, y).
- Write a function
- Validate the features.
- Build a new expectation suite for the features.
- Create expectations to validate all features. One expectation type applied on one or more features but we should run expecatations on all features. For example, you can expect one hot encoding columns to be 0 or 1.
- Create a batch request where the data asset is a pandas dataframe. Do not forget that here the pipeline tasks are exchanging data and not only metadata.
- Create a checkpoint to check the validitiy of the features.
- Write a function
validate_featuresinsrc/data.pyto validate the features by running the checkpoint. - Send to the next step, the dataframe (X, y).
- Load the features.
- Create a function
load_featuresinsrc/data.pyto do as follows.- Load and version the features X and the target y in artifact store of ZenML.
- Use
zenml.save_artifactmethod with a name likefeatures_targetorX_yand same version as the data sample version. Here we will use the custom versions as tags, and let ZenML automatically increments the version.import zenml # save the artifact as follows: # df is your dataframe # name is the artifact name # version is your custom version (set it to tags) # I did not set `version` argument since I want an automatic versioning zenml.save_artifact(data = df, name = "features_target", tags=[version]) from zenml.client import Client client = Client() # We can retrieve our artifact with a specific custom version `v5` as follows: l = client.list_artifact_versions(name="features_target", tag="v5", sort_by="version").items # Descending order l.reverse() # l here is a list of items and l[0] will retrieve the latest version of the artifact df = l[0].load() # pd.DataFrame
- Ensure that you can retrieve your version from ZenML store. (Use
zenml.load_artifact) - [optional task related to Feast] Persist the features (X, y) in a parquet file
data/processed/features.parquet.
- Create a function
- Extract the data sample from the data store.
- Create a DAG (
pipelines/data_prepare_dag.py) to run the previous ZenML pipeline when all the tasks in data extraction pipeline (pipelines/data_extract_dag.py) are successful (useExternalTaskSensor) and then (load the features to a feature store if you prefer (optional)). If the first pipeline is failed then we should not run the second pipeline. This DAG will ensure the automataion of data preparation. The DAG should be scheduled to run every 5 minutes (same schedule as first pipeline). This pipeline should be atomic such that if a single task/step fails, then all of the tasks/steps fail. The tasks here are:- An external task sensor to wait for completion of first pipeline (data extraction.
- A Bash task to run the ZenML pipeline.
- [Optional task] Load the features to a feature store (parquet file as a data source).
- Create a file source and read the features from the parquet file.
- Add
timestamp,idfields to the dataframe (X, y). If your data hastimestampfield, then you can use it. - Create an offline feature view with defined schema.
- Create a feature service to retrieve all features.
- Check if you can retrieve features from the offline store.
Note: Notice that this source code should be added to the folder where feature repo is initialized (e.g.services/feast/feast_project/feature_repo/bank_repo.pyin my case) and you can run this source code by executing a command line as follows:
feast -c services/feast/feast_project/feature_repo applyfeast -c services/feast/feast_project/feature_repo ui
- For each function/method you wrote/defined in
srcfolder, write at least one test function intestsfolder and test your modules/classes/functions. - Make sure that you push your changes to Github for submission.
Important note:
Do not write the business logic code in dag definition files in pipelines folder. You should write them in src folder in src/data.py module, then you can call them from pipelines folder when you create dags. This is true for all pipelines (Airflow and ZenML). You should introduce the code in src for regular testing (pytest). You can test pipelines using airflow dags test subcommand.
Info: ZenML actually versions the artifacts and store them in a local store in the file system. So for this project, we do not need to use a special feature store as it will add more unnecessary complexity. It is good to mention that Feast does not have a versioning feature and you need to do so using other tools like dvc whereas other feature store tools such as featureform may support versioning but we will not cover it in this project.
B. Report [Only for Master’s students]
Complete the following chapters:
- Chapter 3: Data preparation
- The data preparation phase covers all activities to construct the final dataset (data that will be fed into the machine learning pipelines) from the initial raw data. Data preparation tasks are likely to be performed multiple times and not in any prescribed order. Tasks include table, record and attribute selection as well as transformation and cleaning of data for modeling phase.
- Section 3.1. Select data
- Decide on the data to be used for analysis. Criteria include relevance to the machine learning goals, quality and technical constraints such as limits on data volume or data types. Note that data selection covers selection of attributes (columns) as well as selection of records (rows) in a table.
- List the data to be included/excluded and the reasons for these decisions.
- Section 3.2. Clean data
- Raise the data quality to the level required by the selected machine learning techniques. This may involve selection of clean subsets of the data, the insertion of suitable defaults or more ambitious techniques such as the estimation of missing data by modeling.
- Describe what decisions and actions were taken to address the data quality problems reported during the verify data quality task of the business and data understanding phase. Transformations of the data for cleaning purposes and the possible impact on the analysis results should be considered.
- Section 3.3. Construct data
- This task includes constructive data preparation operations such as the production of derived attributes, entire new records or transformed values for existing attributes.
- Derived attributes are new attributes that are constructed from one or more existing attributes in the same record.
- Describe the creation of completely new records.
- Example: create records for customers who made no purchase during the past year.There was no reason to have such records in the raw data, but for modeling purposes it might make sense to explicitly represent the fact that certain customers made zero purchases.
- Section 3.4. Inegrate data
- You can omit this section due to using only one data source.
- Section 3.5. Standardize data
- Describe normalization methods used to unify the data. Do not forget that the data fed to the modeling stage is a single object.
- Merge data containers if you have more than one.
- Describe how you develop a uniform schema for your dataset