Phase I - Business and data understanding
Course: MLOps engineering
Author: Firas Jolha
Colab notebook
Agenda
- Phase I - Business and data understanding
- Colab notebook
- Agenda
- Intro to MLOps
- CRISP-ML
- CRISP-DM Vs. CRISP-ML
- CRISP-ML - Phase I : Business and Data understanding
- Hydra
- DVC
- Pytest
- Great Expectations (GX)
- Data Quality
- Project tasks
- References
Intro to MLOps
Machine learning models are complicated. Every use case has a long list of challenges at every stage, from concept to training to deployment.
Existing DevOps strategies, which help businesses streamline software development do not always apply. Machine learning operations, or MLOps, follows the spirit of DevOps. It helps businesses use ML efficiently and reliably.
If you are already familiar with the concept of DevOps, you may think that MLOps is just DevOps for machine learning. While the concept and goals are similar, the details are significantly different.
If DevOps is a set of practices for building a traditional house, MLOps is the process for building a house on Mars. The builders still need to plan the basics: architecture, utilities, and labor. However, they also need critical input and feedback from experts in space logistics and the Martian environment. They need to get the right materials to Mars, plus they must ensure that the house can withstand the harsh Martian conditions.
While MLOps and DevOps both care about scalability and reproducibility, their scale, complexity, and methods can be significantly different.
Machine Learning: The Short Version
Imagine a pizza restaurant franchise that wants to use ML to sell more pizza. The team responsible for this project might follow these steps:
- Gather data that they think will help the model learn
- Study the data to understand how the model should use it
- Prepare the data so that a computer can read it all easily
- Create the model, giving it a goal and telling it how to use the datasets
- Train the model by giving it test data and letting it run
- Evaluate the model to find errors and optimize model performance
- Deploy the model to active use
- Monitor the model to make sure it continues to work as expected
Example: The team wants to make an ML model that suggests discounts, coupons, and other promotions. The team names it “Pizzatron”. Pizzatron runs on current sales data and sends promotion recommendations to store owners. It is simple, isn’t it?
Machine Learning is Not Simple
With our simplified Pizzatron example, there are complexities at every phase in the machine learning development chain. To begin with, in practice, the “team” in the example usually consists of three or more teams. To do an analysis this well, you need data scientists. Experts in building and deploying ML systems are known as ML engineers. Teams of software engineers work together to prepare data and construct models.
Even if we assume that everyone involved does their job well, there are bound to be mistakes.
- What if the initial metrics had a flaw that made Pizzatron “learn” that pineapple pizza is a big seller at Christmas?
- What if the designers did not account for available materials, so Pizzatron often promotes out-of-stock ingredients?
- If Pizzatron was developed using data from the United States, will it know how to behave for franchises in Italy and Japan?
Pizzatron requires constant validation. Any problems send Pizzatron right back to the development teams, who must go through the development steps, again. ML models can come back, again and again, to cause trouble for their creators.
MLOps Makes it Better
If these teams are going to do complicated work together on a regular basis, they need a process. They need automation, defined stages, and workflows. This is exactly the structure that MLOps aims to provide. As explained by the authors of ml-ops.org:
“With [MLOps], we want to provide an end-to-end machine learning development process to design, build, and manage reproducible, testable, and evolvable ML-powered software.”
MLOps is a set of processes and automation for managing models, data and code to improve performance stability and long-term efficiency in ML systems.
People and personas

MLOps principles
An optimal MLOps experience [as] one where Machine Learning assets are treated consistently with all other software assets within a CI/CD environment. Machine Learning models can be deployed alongside the services that wrap them and the services that consume them as part of a unified release process. In the following, we describe a set of important concepts in MLOps such as Iterative-Incremental Development, Automation, Continuous Deployment, Versioning, Testing, Reproducibility, and Monitoring.
1. Iterative-Incremental Process
The fastest way to build an ML product is to rapidly build, evaluate, and iterate on models. This includes three core phases:

- Design
- business understanding
- data understanding
- Design a plan to solve the business problem
- ML Experimentation and Development
- Start with a Proof-of-Concept ML Model
- Optimize it and select the best one
- Deliver a stable quality ML model that we will run in production
- ML Operations
- Deliver the previously developed ML model in production
- Testing, versioning, continuous delivery, and monitoring
2. Automation
The level of automation of the Data, ML Model, and Code pipelines determines the maturity of the ML process.
How do you know?
- With increased maturity:
- the velocity for the training of new models is also increased.
- The complete ML-workflow steps are automated without any manual intervention.
- Triggers for automated model training and deployment can be calendar events (Apache Airflow).
- Automated testing helps discovering problems quickly and in early stages.
To adopt MLOps, there is three levels of automation, starting from the initial level with manual model training and deployment, up to running both ML and CI/CD pipelines automatically.
- Manual process
- This level has an experimental and iterative nature.
- Every step in each pipeline, such as data preparation and validation, model training and testing, are executed manually.
- ML pipeline automation
- The next level includes the execution of model training automatically.
- We have here the continuous training of the model.
- Whenever new data is available, the process of model retraining is triggered.
- This level of automation also includes data and model validation steps.
- CI/CD pipeline automation
- We introduce a CI/CD system to perform fast and reliable ML model deployments in production.
- The core difference from the previous step is that we now automatically build, test, and deploy the Data, ML Model, and the ML training pipeline components (code).
3. Continuous X
- Continuous Integration (CI) extends the testing and validating code and components by adding testing and validating data and models.
- Continuous Delivery (CD) concerns with delivery of an ML training pipeline that automatically deploys another ML model prediction service.
- Continuous Training (CT) is unique to ML systems property, which automatically retrains ML models for re-deployment.
- Continuous Monitoring (CM) concerns with monitoring production data and model performance metrics, which are bound to business metrics.
4. Versioning
The goal of the versioning is to treat ML training scrips, ML models and data sets for model training as first-class citizens in DevOps processes by tracking ML models and data sets with version control systems.
- ML models can be retrained based upon new training data.
- Models may be retrained based upon new training approaches.
- Models may degrade over time.
- Models may be deployed in new applications.
- Models may be subject to attack and require revision.
- Models can be quickly rolled back to a previous serving version.
- Corporate or government compliance may require audit or investigation on both ML model or data, hence we need access to all versions of the productionized ML model.
- Data may reside across multiple systems.
- Data may only be able to reside in restricted jurisdictions.
- Data storage may not be immutable.
- Data ownership may be a factor.
5. Experiments Tracking
In contrast to the traditional software development process, in ML development, multiple experiments on model training can be executed in parallel before making the decision what model will be promoted to production.
6. Testing
The complete development pipeline includes three essential components, data pipeline, ML model pipeline, and application pipeline. In accordance with this separation we distinguish three scopes for testing in ML systems: tests for features and data, tests for model development, and tests for ML infrastructure.
7. Monitoring
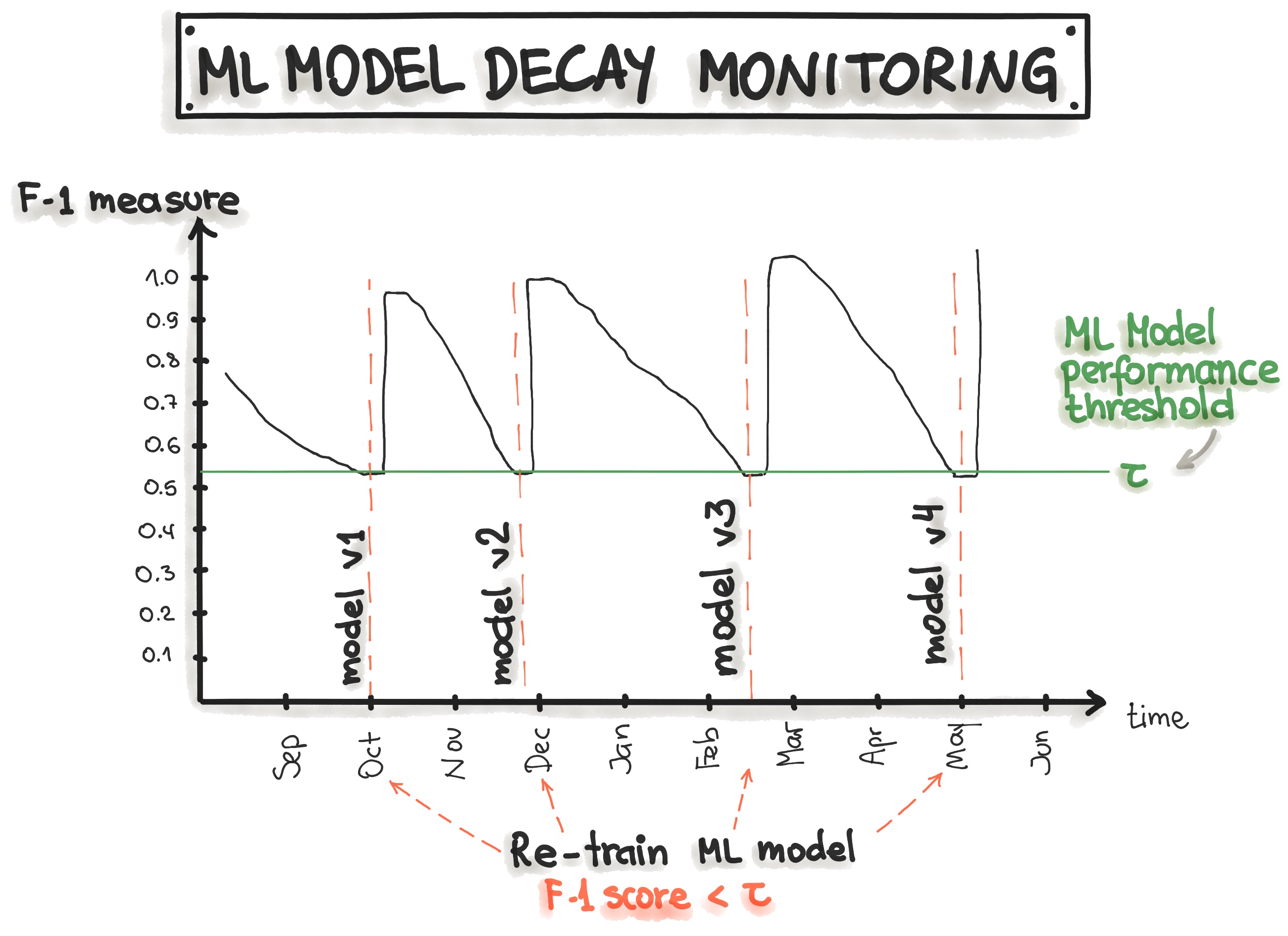
The picture below shows that the model monitoring can be implemented by tracking the precision, recall, and F1-score of the model prediction along with the time. The decrease of the precision, recall, and F1-score triggers the model retraining, which leads to model recovery.
8. “ML Test Score” System
The “ML Test Score” measures the overall readiness of the ML system for production. The final ML Test Score is computed as follows:
- For each test, half a point is awarded for executing the test manually, with the results documented and distributed.
- A full point is awarded if the there is a system in place to run that test automatically on a repeated basis.
- Sum the score of each of the four sections individually: Data Tests, Model Tests, ML Infrastructure Tests, and Monitoring.
- The final ML Test Score is computed by taking the minimum of the scores aggregated for each of the sections: Data Tests, Model Tests, ML Infrastructure Tests, and Monitoring.
After computing the ML Test Score, we can reason about the readiness of the ML system for production. The following table provides the interpretation ranges:
| Points | Description |
|---|---|
| 0 | More of the research project than a productionized system. |
| (0,1] | Not totally untested, but it is worth considering the possibility of serious holes in reliability. |
| (1,2] | There has been first pass at basic productionization, but additional investment may be needed. |
| (2,3] | Reasonably tested, but it is possible that more of those tests and procedures may be automated. |
| (3,5] | Strong level of automated testing and monitoring. |
| >5 | Exceptional level of automated testing and monitoring. |
9. Reproducibility
Reproducibility in a machine learning workflow means that every phase of either data processing, ML model training, and ML model deployment should produce identical results given the same input.
10. Loosely Coupled Architecture (Modularity)

11. ML-based Software Delivery Metrics (4 metrics from “Accelerate”)
These metrcs are:
- Deployment Frequency
How often does your organization deploy code to production or release it to end-users?
- Lead Time for Changes
How long does it take to go from code committed to code successfully running in production?
- Mean Time To Restore
How long does it generally take to restore service when a service incident or a defect that impacts users occurs (e.g., unplanned outage or service impairment)?
- Change Fail Percentage.
What percentage of changes to production or released to users result in degraded service (e.g., lead to service impairment or service outage) and subsequently require remediation (e.g., require a hotfix, rollback, fix forward, patch)?
These metrics have been found useful to measure and improve ones ML-based software delivery.
The complete ML development pipeline includes three levels where changes can occur: Data, ML Model, and Code. This means that in machine learning-based systems, the trigger for a build might be the combination of a code change, data change or model change.
CRISP-ML
Standardization of approaches and processes makes it possible to unify and scale the best practices of research and development management, including extending them to other domains. For example, CRISP-DM (Cross-Industry Standard Process for Data Mining) as the most common methodology for performing data science projects describes their life cycle in 6 phases, each of which includes a number of tasks.
A similar approach to machine learning was published in 2012 under the name CRISP-ML(Q). It is an acronym for CRoss-Industry Standard Process model for the development of Machine Learning applications with Quality assurance methodology. Based on CRISP-DM, the CRISP-ML(Q) process model describes six steps:
- Understanding of business and data;
- Data engineering (data preparation);
- Machine learning modeling;
- Quality assurance of machine learning applications;
- Deploying an ML model;
- Monitoring and maintenance of the ML system.
Datasets in Research vs. Industry
Datasets themselves are a core part of that success of models. This is why data gathering, preparation, and labeling should be seen as an iterative process, just like modeling. Start with a simple dataset that you can gather immediately, and be open to improving it based on what you learn.
This iterative approach to data can seem confusing at first. In ML research, performance is often reported on standard datasets that the community uses as benchmarks and are thus immutable. In traditional software engineering, we write deterministic rules for our programs, so we treat data as something to receive, process, and store.

ML engineering combines engineering and ML in order to build products. Our dataset is thus just another tool to allow us to build products. In ML engineering, choosing an initial dataset, regularly updating it, and augmenting it is often the majority of the work. This difference in workflow between research and industry is illustrated in the figure above.
ML Problem framing
- Problem framing helps determine your project’s technical feasibility and provides a clear set of goals and success criteria.
- When considering an ML solution, effective problem framing can determine whether or not your product ultimately succeeds.
At a high level, ML problem framing consists of two distinct steps:
- Determining whether ML is the right approach for solving a problem.
- Framing the problem in ML terms to ensure that an ML approach is a good solution to the problem before beginning to work with data and train a model.
A. To understand the problem, perform the following tasks:
- State the goal for the product you are developing or refactoring.
| App | Goal |
|---|---|
| Weather app | Calculate precipitation in six-hour increments for a geographic region. |
| Banking app | Identify fraudulent transactions. |
- Determine whether the goal is best solved using, predictive ML, generative AI, or a non-ML solution.
- Verify you have the data required to train a model if you’re using a predictive ML approach.
B. After verifying that your problem is best solved using either a predictive ML or a generative AI approach, you’re ready to frame your problem in ML terms. You frame a problem in ML terms by completing the following tasks:
- Define the ideal outcome and the model’s goal.
- Identify the model’s output.
- Define success metrics.
I recommend to comprehend this course from Google (https://developers.google.com/machine-learning/problem-framing)
ML Canvas
Confirming the feasibility before setting up the ML project is a best practice in an industrial setting. Applying the Machine Learning Canvas (ML Canvas) framework would be a structured way to perform this task. The ML Canvas guides through the prediction and learning phases of the ML application. In addition, it enables all stakeholders to specify data availability, regulatory constraints, and application requirements such as robustness, scalability, explainability, and resource demand.
The Machine Learning Canvas is a template for developing new or documenting existing predictive systems that are based on machine learning techniques. It is a visual chart with elements describing a question to predict answers to (with machine learning), objectives to reach in the application domain, ways to use predictions to reach these objectives, data sources used to learn a predictor, and performance evaluation methods.
The template can be downloaded from here.

CRISP-DM Vs. CRISP-ML
There are not a lot of case studies of CRISP-ML published in the Internet, but you can find a lot studies for CRISP-DM process. CRISP-ML combines business and data understanding phases of CRISP-DM into one phase but these phases have similar objectives. So, the case study here I will be present is related to CRISP-DM, with some modifications. There is another case study of CRISP-ML mentioned in References section.
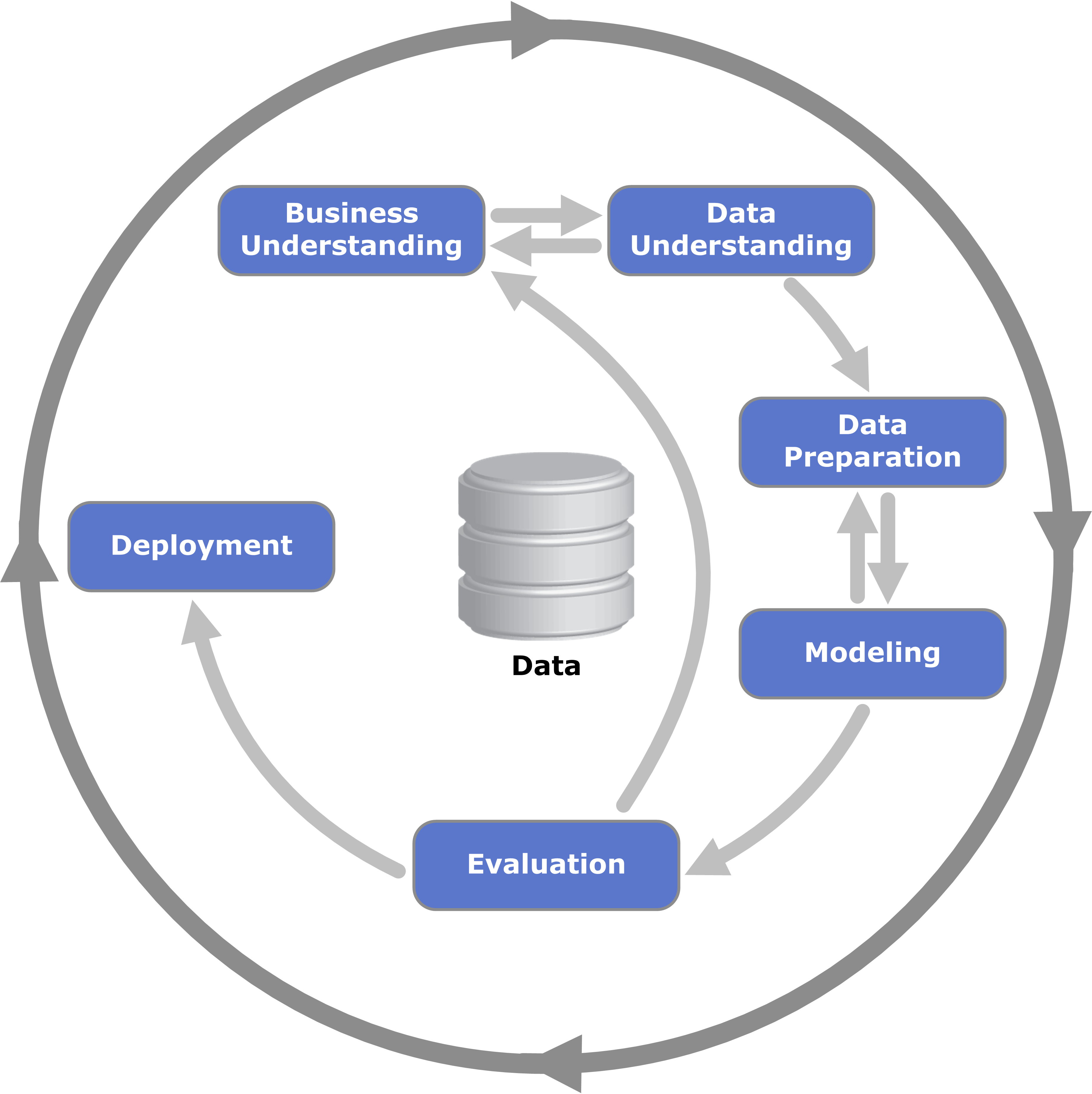
CRISP-DM

CRISP-ML
CRISP-ML - Phase I : Business and Data understanding
The initial phase is concerned with tasks to define the business objectives and translate it to ML objectives, to collect and verify the data quality and to finaly assess the project feasibility.

Follow the attached notebook for more details.
 Hydra
Hydra
Hydra is an open-source Python framework that simplifies the development of research and other complex applications. The key feature is the ability to dynamically create a hierarchical configuration by composition and override it through config files and the command line. Some features of Hydra:
- A Python framework for configuration management from Facebook Research.
- Dynamically builds a hierarchical configuration composable from multiple sources
- Configuration can be specified or overridden from the command line
- Configuration can be structured using OmegaConf package
- Run multiple jobs with different arguments with a single command (ML Experimenting)
OmegaConf is a YAML based hierarchical configuration system, with support for merging configurations from multiple sources (files, CLI argument, environment variables) providing a consistent API regardless of how the configuration was created. OmegaConf also offers runtime type safety via Structured Configs.
To get started using Hydra, you can watch this video
Demo
Here I will present some of the features of this tool and some of its use cases. The official website has good tutorials and guides, so follow them to learn more about the tool.
Install Hydra
# It is a Python package.
pip install hydra-core
Note: Python decorator is a function that takes another Python function and extends the behavior of the latter function without explicitly modifying it. Example:
def mydecorator(func):
def wrapper():
print("Before")
func()
print("After")
return wrapper
@mydecorator
def say_whee():
print("Welcome!")
Basic example
Configuration file: configs/main.yaml
db:
driver: mysql
user: james
password: secret
Python file: src/app.py
import hydra
from omegaconf import DictConfig, OmegaConf
@hydra.main(version_base=None, config_path="configs", config_name="main")
def app(cfg : DictConfig = None) -> None:
print(OmegaConf.to_yaml(cfg))
print(cfg.db.password)
print(cfg['db']['password'])
if __name__ == "__main__":
app()
You can learn more about OmegaConf here later.
Note: Create a new virtual environemnt using venv or conda in VS code.
We can run our simple application as:
python app.py
The output will be:
db:
driver: mysql
user: james
password: secret
secret
secret
We will have the Hydra output directory outputs and the application log file. Inside the configuration output directory we have:
config.yaml: A dump of the user specified configurationhydra.yaml: A dump of the Hydra configurationoverrides.yaml: The command line overrides used
And in the main output directory:
app.log: A log file created for this run
We can override our configuration as follows:
python app.py db.password=secret2 +db.dbname=project_db ++version=1.2.4 ~db.driver
The output:
db:
user: james
password: secret2
dbname: project_db
version: 1.2.4
secret2
secret2
Composition example
You may want to alternate between two different databases. To support this create a config group named db, and place one config file for each alternative inside. The directory structure of our application now looks like:
├── configs
│ ├── main.yaml
│ ├── db
│ ├── mysql.yaml
│ └── postgresql.yaml
│
├── src
└── my_app.py
The primary configuration file: configs/main.yaml
defaults:
- db: mysql
db:
user: james
The configuration file: configs/db/mysql.yaml
driver: mysql
password: secret_mysql
user: jones
The configuration file: configs/db/postgresql.yaml
driver: psql
password: secret_psql
user: jones
defaults is a special directive telling Hydra to use db/mysql.yaml when composing the configuration object. The resulting cfg object is a composition of configs from defaults with configs specified in your main.yaml.
You can now choose which database configuration to use and override values from the command line:
python src/app.py db=postgresql
The output:
db:
driver: psql
password: secret_psql
user: james
secret_psql
secret_psql
Use _self_ enrty in Defaults List, and check what changes in the output.
The _self_ entry determines the relative position of this config in the Defaults List. If it is not specified, it is added automatically as the last item.
Multirun example
You can run your function multiple times with different configurations easily with the --multirun|-m flag.
python src/app.py --multirun db=mysql,postgresql
Missing values and Value interpolation
We can populate config values dynamically via value interpolation. We can specify missing values in configuration files using ??? literal.
The primary configuration file configs/main.yaml.
db:
user: james
age: ???
current_age: ${db.age}
age_string: "This is my age ${db.current_age}"
defaults:
- db: mysql
- _self_
The script file: src/app.py
"""
My application
"""
import hydra
from omegaconf import DictConfig, OmegaConf
@hydra.main(config_path="../configs", config_name="main", version_base=None)
def app(cfg: DictConfig = None):
"""
Entry function of my application
"""
print(OmegaConf.to_yaml(cfg))
print(cfg.db.password)
print(cfg['db']['password'])
print(cfg.db.age)
print(cfg.db.current_age)
print(cfg.db.age_string)
if __name__ == "__main__":
app()
The command line:
python src/app.py db.age=10
The output:
db:
driver: mysql
password: secret_mysql
user: james
age: 10
current_age: ${db.age}
age_string: This is my age ${db.current_age}
secret_mysql
secret_mysql
10
10
This is my age 10
Non-config group defaults
Sometimes a config file does not belong in any config group. You can still load it by default. Here is an example for some_file.yaml.
defaults:
- some_file
Config files that are not part of a config group will always be loaded. They cannot be overridden. Prefer using a config group.
Compose API
The compose API can compose a config similarly to @hydra.main() anywhere in the code. The Compose API is useful when @hydra.main() is not applicable.
Prior to calling compose(), you have to initialize Hydra: This can be done by using the standard @hydra.main() or by calling one of the initialization methods listed below:
initialize(): Initialize with a config path relative to the callerinitialize_config_module(): Initialize with config_module (absolute name)initialize_config_dir(): Initialize with a config_dir on the file system (absolute path)
All 3 initialization ways can be used as methods or contexts. When used as methods, they are initializing Hydra globally and should only be called once. When used as contexts, they are initializing Hydra within the context and can be used multiple times.
Example:
from hydra import compose, initialize
from omegaconf import OmegaConf
if __name__ == "__main__":
# context initialization
with initialize(version_base=None, config_path="configs", job_name="test_app"):
cfg = compose(config_name="main", overrides=["db=mysql", "db.user=me"])
print(OmegaConf.to_yaml(cfg))
# global initialization
initialize(version_base=None, config_path="configs", job_name="test_app")
cfg = compose(config_name="main", overrides=["db=mysql", "db.user=me"])
print(OmegaConf.to_yaml(cfg))
Three Hydra initializers:
initialize
Initializes Hydra and adds theconfig_pathto the config search path. Theconfig_pathis relative to the parent of the caller.initialize_config_module
Initializes Hydra and adds theconfig_moduleto the config search path. The config module must be importable (an__init__.pymust exist at its top level)initialize_config_dir
Initializes Hydra and add an absolute config dir to the config search path. Theconfig_diris always a path on the file system and is must be an absolute path. Relative paths will result in an error.
Structured Configs
Structured Configs use Python dataclasses to describe your configuration structure and types. We will not cover this section here, but you can learn about it on your own from here.
 DVC
DVC
Data Version Control (DVC) is a free, open-source tool for data management. It allows to track large datasets and version the data.
💫 DVC is your “Git for data”!
Install DVC
pip install dvc
We will use a local directory as a remote storage for versioning data files. You can check the documentation if you want to install for a different remote storage.
Initialize DVC repository
- Open your project repository in VS code and initialize DVC repository by running the command line:
dvc init
There is a VS code extension for DVC, you can install it from here.
This will initialize the DVC repository. The output is:

A few internal files are created that should be added to Git.

We should commit this change to Git as follows:
git add .
git commit -m "initialize DVC"
DVC is technically not a version control system by itself! It manipulates .dvc files, whose contents define the data file versions. Git is already used to version your code, and now it can also version your data alongside it.
The internal files:
.dvcfiles (“dot DVC files”) are placeholders to track data files and directories..dvc/config: This is the default DVC configuration file. It can be edited by hand or with thedvc configcommand..dvc/.gitignore: This is a.gitignorefile to untrack the foldersconfig.local,/tmp,/cache..dvc/config.local: This is an optional Git-ignored configuration file, that will overwrite options in.dvc/config. This is useful when you need to specify sensitive values (secrets, passwords) which should not reach the Git repo (credentials, private locations, etc). This config file can also be edited by hand or withdvc config --local..dvc/cache: Default location of the cache directory. The cache stores the project data in a special structure. The data files and directories in the workspace will only contain links to the data files in the cache..dvc/tmp: Directory for miscellaneous temporary files.
The metafiles of DVC are typically versioned with Git, as DVC does not replace its Git version control features, but rather extends on them.
Configure a remote storage
We will use a local directory as a remote storage but feel free to use the supported remote storage options if you have sufficient access. DVC remotes are similar to Git remotes (e.g. GitHub or GitLab hosting), but for cached data instead of code.
- Create
datastorefolder in the root directory of the project repository. - Add
localstoreas a remote storage.
dvc remote add --default localstore $PWD/datastore
# localstore is a placeholder for the remote storage
# $PWD/datastore is the path of the remote storage
# Add the data store to .gitignore to untrack it
echo datastore >> .gitignore
This command line will modify the .dvc/config file and you need to commit this change to Git repo.
- You can define more than one remote storage.
- It is better to use an absolute path to define the local path of the remote storage.
- We need to specify one remote storage as default.
- Commit the change to Git repo.
git add .dvc/config
git commit -m "add remote storage"
Tracking data
Notes on data versioning using DVC:
- Before tracking the data, make sure that you committed the changes to Git repository.
- Everytime you get a new data (change in the data), you should commit the previous version such that each data version should be tracked in a single git commit. This allows to restore the data with a specific version by checking out its commit.
- It is useful to tag the Git commit of each data version, such that switching the data versions will be easy. If you do not use tags, then you need to know the commit hash for the data version to restore.
To version a data file data.csv:
- Download/Add the data file
data.scvto your Git repository. - Initialize DVC repository (only once per repository).
- Add
data.csvto DVC repository. - Add the changes (data.csv.dvc) to Git repository.
- Commit the changes to Git repository.
- Push the commit to Github.
- Tag the commit and push the tag to Github.
- Push the data to the DVC remote registry.
Example
Here I will download my data data.csv, version it, introduce a change to it, after that I will version the change, and switch between versions:
- Given the data url, you can download it using
wgetas follows:
mkdir -p data/raw
wget https://archive.ics.uci.edu/static/public/222/data.csv -O data/raw/data.csv
If your data is stored in Git or DVC repository then you can download it using dvc as follows:
dvc get https://github.com/iterative/dataset-registry get-started/data.xml -o data/raw/data.csv
- Initialize DVC repository. We did it in the previous section.
- Start tracking the data in DVC.
dvc add data/raw/data.csv

DVC stores information about the added file in a special .dvc file named data/raw/data.csv.dvc. This small, human-readable metadata file acts as a placeholder for the original data for the purpose of Git tracking. The actual data file data.csv is added to .gitignore to untrack it from Git repository.
- Track changes in Git.
git add data/raw/data.csv.dvc data/raw/.gitignore
Now the metadata about your data is versioned alongside your source code, while the original data file was added to .gitignore.
- Commit the changes to Git repository.
git commit -m "add raw data"
- Push the commit to Github.
git push
- Tag the commit and push the tag to Github
git tag -a "v1.0" -m "add data version v1.0"
git push --tags
- Push the data to the DVC remote registry.
dvc push
Info: DVC tracks the data in the remote storage, whereas Git tracks the hash code of the files.
Here I will download a new version of the data data.csv and version it.
9. Download new data.
wget https://archive.ics.uci.edu/static/public/96/data.csv -O data/raw/data.csv
You can check the status of DVC repository by running:
dvc status
The option -c|--cloud allows to show status of a local cache (.dvc/cache) compared to the remote repository.
- Add the file to DVC repository
dvc add data/raw/data.csv
- Add the changes like data.csv.dvc to Git repository.
git add .
- Commit the changes
git commit -m "add new data"
- Push the commit to Github.
git push
- Tag the commit and push to Github.
git tag -a "v2.0" -m "A new version of the data V2.0"
git push --tags
- Push the data to the DVC remote registry.
dvc push
You can list the tags of a Git repo as:
git tag
Switch between data versions
You actually can delete the file from data folder since it is stored in the remote storage. You will notice that the data is locally saved in its cache folder .dvc/cache using file hashes.
Using Git
You can restore the previous versions of the data from Git repository by checking out the corresponding commit. You can use the tags that you defined as follows:
git checkout v1.0 data/raw/data.csv.dvc
This will restore the data.csv.dvc metafile.
In order to restore the actual file, you need to checkout DVC too:
dvc checkout
You can add and commit the selected version then push it.
git commit data/raw/data.csv.dvc -a -m "Restored data v1.0"
You do not need to push it to DVC again since this version is already stored in the remote storage.
Notice that if you checkout without specifying the file (e.g. git checkout v1.0), then all other tracked files (e.g. config files, source codes, …etc) with the same commit “v1.0” will also be checked out (be careful). This will also detach the HEAD pointer to point to the commit which contains the data of version v1.0. You can attach it to main branch by running git switch main.
Using dvc.api Python API
DVC comes as a VS Code Extension, as a command line interface, and as a Python API. Here we will use dvc.api to obtain the data files based on the selected version.
# configs/main.yaml
data:
version: 1.0
path: data/raw/data.csv
repo: .
remote: localstore
# src/app.py
import pandas as pd
import hydra
import dvc.api
import os.path
@hydra.main(config_path="../configs", config_name="main", version_base=None)
def app(cfg=None):
url = dvc.api.get_url(
path=os.path.join("data/raw/data.csv"), # the path to the file in the remote storage
repo=os.path.join(cfg.data.repo), # The url/path to the remote stage
rev=str(cfg.data.version), # the version of the data to restore
remote=cfg.data.remote # The placeholder of the remote storage
)
print(url) # It will be the path of the file in the remote storage
# Read the data
df = pd.read_csv(url)
print(df.head())
if __name__=="__main__":
app()
You can set the version in the config file and read the data with the requested version.
- Notice that the file
data.csvin the folderdata, can be deleted for some reason, and you still need to set its path the same when you added to the DVC repository since DVC also tracks the path of the file indata.csv.dvcfile. - If the data file
data/data.csvis deleted, we still can restore it by runningdvc pull, since it is stored in the remote storage. - The metafile
data.csv.dvcis important to not delete it to know how to restore your actual data file.
Some other functions which could be useful from dvc.api:
from dvc.api import DVCFileSystem
fs = DVCFileSystem(".") # /path/to/local/repository
url = "https://remote/repository" # remote repository
fs = DVCFileSystem(url, rev="main")
# Open a file
with fs.open("data.csv", mode="r") as f:
print(f.readlines()[0])
# Reading a file
text = fs.read_text("get-started/data.xml", encoding="utf-8")
contents = fs.read_bytes("get-started/data.xml")
# Listing all DVC-tracked files recursively
fs.find("/", detail=False, dvc_only=True)
# Listing all files (including Git-tracked)
fs.find("/", detail=False)
# Downloading a file or a directory
fs.get_file("data/data.xml", "data.xml")
## This downloads "data/data.xml" file to the current working directory as "data.xml" file
fs.get("data", "data", recursive=True)
## This downloads all the files in "data" directory - be it Git-tracked or DVC-tracked into a local directory "data".
 Pytest
Pytest
Testing is one of the important practices to do in MLOps pipelines. Writing and maintaining boilerplate tests is not easy, so you should leverage all the tools at your disposal to make it as painless as possible. pytest is one of the best tools that you can use to boost your testing productivity. In ML projects, we need to test or validate data, code and model. pytest is intended to validate the codebase of the project.
Install pytest
pip install pytest
AAA pattern
The AAA (Arrange-Act-Assert) pattern is a widely recognized and effective approach to structuring unit tests. This pattern provides a clear and organized structure for writing tests, enhancing readability and maintainability. By following the AAA pattern, developers can create robust and reliable unit tests that validate the behavior of their code.
The Arrange-Act-Assert pattern:
- Arrange, or set up, the conditions for the test
- Act, or perform, the specific action or method being tested by calling some function or method
- Assert, or verify, that the actual results match the expected results.
Example:
def sum(a, b):
return a + b
def test_sum():
# Arrange
x = 1
y = 1
# Act
result = sum(x, y)
# Assert
assert result == 2
unittest short demo
If you have written unit tests for your Python code before, then you may have used Python’s built-in unittest module. The package unittest provides a solid base on which to build your test suite, but it has a few shortcomings.
Testing frameworks typically hook into your test’s assertions so that they can provide information when an assertion fails. unittest, for example, provides a number of helpful assertion utilities out of the box. However, even a small set of tests requires a fair amount of boilerplate code.
# tests/dummy.py
def sum(a, b):
return a + b
# tests/test_sum_unittest.py
from unittest import TestCase
from src.dummy import sum
class TryTesting(TestCase):
def test_sum_pn(self):
x = 1
y = -1
result = sum(x, y)
self.assertTrue(result == 0)
def test_sum_pp(self):
x = 1
y = 1
result = sum(x, y)
self.assertGreater(result, 2)
You can run unittest tests from command line using discover option.
python -m unittest discover tests
Note: By default, the test modules and functions, should start with “test*” such as “test_sum”, “test_x.py”, “test_fun”, …etc.
Create test functions in pytest
The module unittest is a built-in testing framework in Python but includes a lot of boilerplate code. pytest simplifies this workflow by allowing you to use normal functions and Python’s assert keyword directly.

pytest vs unittest
Example:
Here I created two dummy functions with their test functions.
# src/dummy.py
def sum(a, b):
return a + b
def mul(a, b):
return a * b
# tests/test_sum.py
from src.dummy import sum
def test_sum_pn():
x = 1
y = -1
result = sum(x, y)
assert result == 0
def test_sum_pp():
x = 1
y = 1
result = sum(x, y)
assert result > 2
# tests/test_mul.py
from src.dummy import mul
def test_mul_pn():
x = 1
y = -1
result = mul(x, y)
assert result < 0
def test_mul_pp():
x = 1
y = 1
result = mul(x, y)
assert result > 0
You can run tests from command line using pytest command.
pytest
If you get an error “ModuleNotFoundError: No module named ‘src’”, then it is probably that you did not add __init__.py file to src and tests folders. Add them and run the command again.
The output:
================= test session starts =================
platform win32 -- Python 3.12.0, pytest-8.2.2, pluggy-1.5.0
rootdir: C:\Users\Admin\mlops\test\mlops-dvc-test01
plugins: hydra-core-1.3.2
collected 4 items
tests\test_mul.py .. [ 50%]
tests\test_sum.py .F [100%]
====================== FAILURES =======================
_____________________ test_sum_pp _____________________
def test_sum_pp():
x = 1
y = 1
result = sum(x, y)
> assert result > 2
E assert 2 > 2
tests\test_sum.py:17: AssertionError
=============== short test summary info ===============
FAILED tests/test_sum.py::test_sum_pp - assert 2 > 2
============= 1 failed, 3 passed in 0.27s =============
Test discovery
pytest is able to find all the tests we want it to run as long as we name them according to the pytest naming conventions which are:
- Test files/modules should be named
test_<something>.pyor<something>_test.py. - Test methods and functions should be named
test_<something>. - Test classes should be named
Test<Something>.
Test Outcomes
So far we’ve seen one passing test and one failing test. However, pass and fail are not the only outcomes possible.
Here are the possible outcomes of a test:
- PASSED (.)—The test ran successfully.
- FAILED (F)—The test did not run successfully.
- SKIPPED (s)—The test was skipped.
- XFAIL (x)—The test was not supposed to pass, and it ran and failed. You can tell pytest that a test is expected to fail by using the
@pytest.mark.xfail()decorator. - XPASS (X)—The test was marked with xfail, but it ran and passed.
- ERROR (E)—An exception happened either during the execution of a fixture or hook function, and not during the execution of a test function.
Failing a test
A test will fail if there is any uncaught exception. This can happen if
- an assert statement fails, which will raise an
AssertionErrorexception, - the test code calls
pytest.fail(), which will raise an exception, or - any other exception is raised (
raisekeyword).
Example
# src/cards.py
from dataclasses import asdict, dataclass
@dataclass
class Card:
summary: str = None
owner: str = None
state: str = "todo"
id: int = 0
def from_dict(cls, d):
return Card(**d)
def to_dict(self):
return asdict(self)
# tests/test_alt_fail.py
import pytest
from src.cards import Card
def test_with_fail():
c1 = Card("sit there", "brian")
c2 = Card("do something", "okken")
if c1 != c2:
pytest.fail("they don't match")
Testing for expected exceptions
We’ve looked at how any exception can cause a test to fail. But what if a bit of code you are testing is supposed to raise an exception? How do you test for that? You use pytest.raises() to test for expected exceptions.
# src/cards.py
class CardsDB:
def __init__(self, db_path):
self._db_path = db_path
# tests/test_no_exceptions
import pytest
from src.cards import CardsDB
def test_no_path_raises():
with pytest.raises(TypeError):
CardsDB()
We can run this test alone as follows:
pytest tests/test_exceptions.py
The output:
================= test session starts =================
platform win32 -- Python 3.12.0, pytest-8.2.2, pluggy-1.5.0
rootdir: C:\Users\Admin\mlops\test\mlops-dvc-test01
plugins: hydra-core-1.3.2
collected 1 item
tests\test_exceptions.py . [100%]
================== 1 passed in 0.04s ==================
Grouping Tests with Classes
So far we have written test functions within test modules. pytest also allows us to group tests with classes.
# tests/test_card.py
from src.cards import Card
class TestEquality:
def test_equality(self):
c1 = Card("something", "brian", "todo", 123)
c2 = Card("something", "brian", "todo", 123)
assert c1 == c2
def test_equality_with_diff_ids(self):
c1 = Card("something", "brian", "todo", 123)
c2 = Card("something", "brian", "todo", 4567)
assert c1 == c2
def test_inequality(self):
c1 = Card("something", "brian", "todo", 123)
c2 = Card("completely different", "okken", "done", 123)
assert c1 != c2
class TestCardIds:
def test_equality_id(self):
c1 = Card("something", "brian", "todo", 123)
c2 = Card("something", "brian", "todo", 122)
assert c1.id == c2.id
def test_equality_with_diff_ids(self):
c1 = Card("something", "brian", "todo", 123)
c2 = Card("something", "brian", "todo", 4567)
assert c1.id != c2.id
def test_inequality(self):
c1 = Card("something", "brian", "todo", 123)
c2 = Card("completely different", "okken", "done", 123)
assert c1.id != c2.id
def test_hello():
assert msg=="hello"
We can run a subset of tests as follows:
- All tests in a class
pytest tests/test_card.py::TestCardIds
- All tests in a module
pytest tests/test_card.py
- Single test function
pytest tests/test_card.py::test_hello
- Single test method
pytest tests/test_card.py::TestCardIds::test_inequality
- All tests in a directory
pytest tests
pytest Fixtures
Fixtures are functions that are run by pytest before (and sometimes after) the actual test functions.
You can use fixtures to get a data set for the tests to work on. Fixtures are also used to get data ready for multiple tests.
import pytest
@pytest.fixture()
def some_data():
"""
Loads some data
"""
df = pd.read_csv("data.csv")
return df
# some_data is the function name (fixture)
def test_some_data(some_data):
assert len(some_data) > 0
The @pytest.fixture() decorator is used to tell pytest that a function is a fixture. When you include the fixture name in the parameter list of a test function, pytest knows to run it before running the test. Fixtures can do work, and can also return data to the test function.
Fixture parameters:
- scope
- Defines the order of when the fixture should run relative to running of all the test function using the fixture.
scope='function'- The default scope for fixtures
- Run once per test function.
scope='module'- Run once per module, regardless of how many test functions or methods or other fixtures in the module use it.
scope='class'- Run once per test class, regardless of how many test methods are in the class.
scope='session'- Run once per session. All test methods and functions using a fixture of session scope share one setup and teardown call.
- You can track the execution order using
--setup-showofpytest
- autouse=True
- enables the fixture to run all of the time.
# tests/test_auto
import pytest
import time
@pytest.fixture(autouse=True, scope="session")
def footer_session_scope():
"""Report the time at the end of a session."""
yield
now = time.time()
print("--")
print(
"finished : {}".format(
time.strftime("%d %b %X", time.localtime(now))
)
)
print("-----------------")
@pytest.fixture(autouse=True)
def footer_function_scope():
"""Report test durations after each function."""
start = time.time()
yield
stop = time.time()
delta = stop - start
print("\ntest duration : {:0.3} seconds".format(delta))
def test_1():
"""Simulate long-ish running test."""
time.sleep(1)
def test_2():
"""Simulate slightly longer test."""
time.sleep(1.23)
import pytest
@pytest.fixture()
def cards_db():
with TemporaryDirectory() as db_dir:
db_path = Path(db_dir)
db = cards.CardsDB(db_path)
yield db
db.close()
def test_empty(cards_db):
assert cards_db.count() == 0
Parametrization
Parametrized testing refers to adding parameters to our test functions and passing in multiple sets of arguments to the test to create new test cases.
# test_param.py
import pytest
@pytest.mark.parametrize("test_input,expected", [("3+5", 8), ("2+4", 6), ("6*9", 42)])
def test_eval(test_input, expected):
assert eval(test_input) == expected
Here, the @parametrize decorator defines three different (test_input,expected) tuples so that the test_eval function will run three times using them in turn.
Markers
In pytest, markers are a way to tell pytest there’s something special about a particular test.
pytest’s builtin markers are used to modify the behavior of how tests run.
- @pytest.mark.filterwarnings(warning): This marker adds a warning filter to the given test.
- @pytest.mark.skip(reason=None): This marker skips the test with an optional reason.
@pytest.mark.parametrize() is a marker.
 Great Expectations (GX)
Great Expectations (GX)
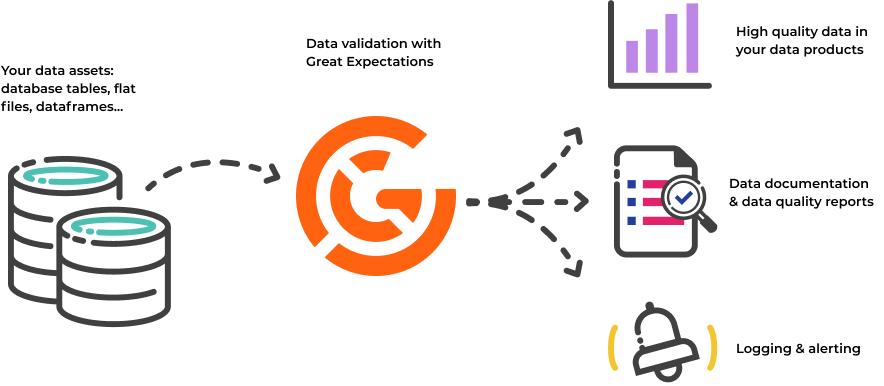
Great Expectations is a tool for validating and documenting your data. Software developers have long known that automated testing is essential for managing complex codebases. Great Expectations brings the same discipline, confidence, and acceleration to data science and data engineering teams. It is a Python library that provides a framework for describing the acceptable state of data and then validating that the data meets those criteria.
Install GX
pip install great_expectations
We can import the package as follows:
import great_expectations as gx
GX Core components
When working with GX you use the following four core components to access, store, and manage underlying objects and processes:
- Data Context: Manages the settings and metadata for a GX project, and provides an entry point to the GX Python API.
- Data Sources: Connects to your data sources, and organizes retrieved data for future use.
- Expectations: Identifies the standards (data requirements) to which your data should conform.
- Checkpoints: Validates a set of Expectations against a specific set of data.
Data context
A Data Context contains all the metadata used by GX, the configurations for GX objects, and the output from validating data.
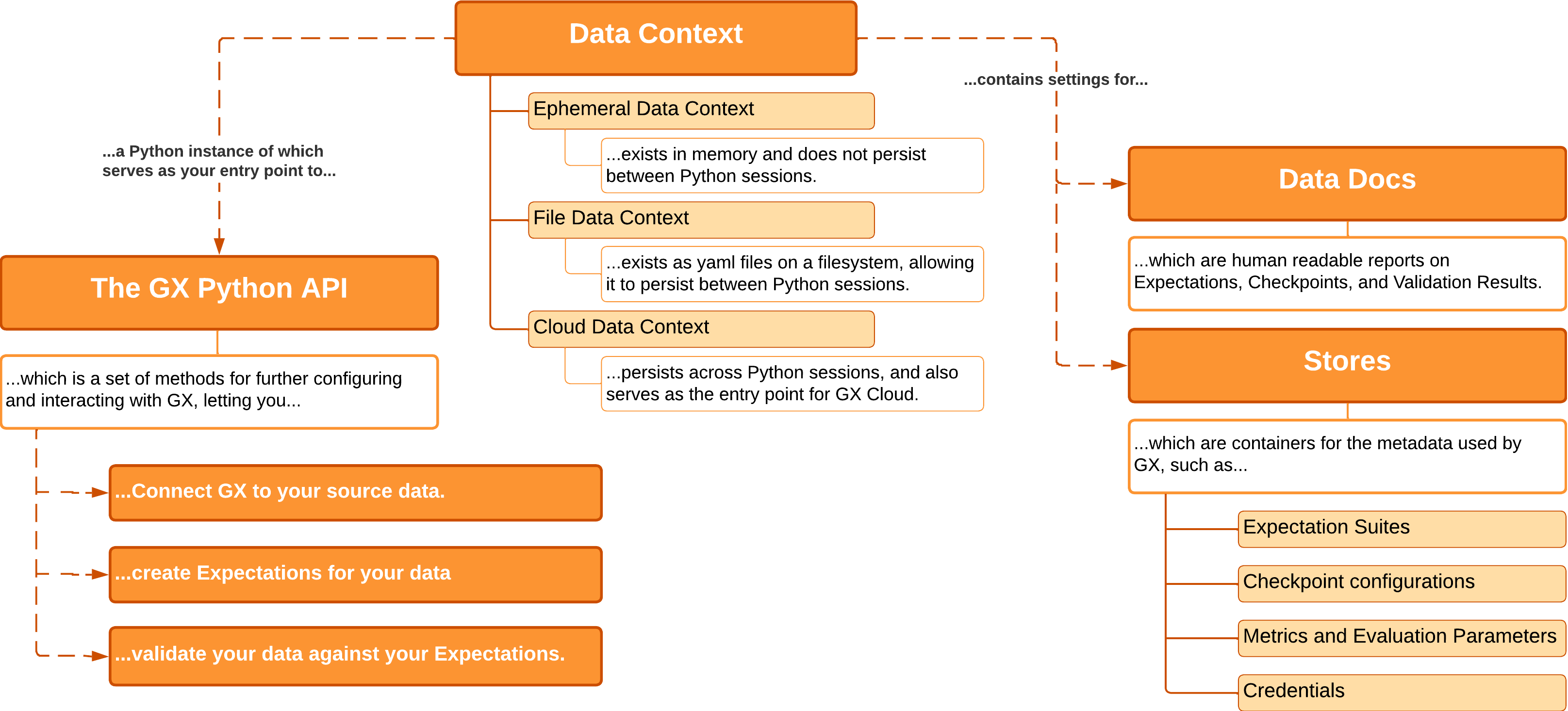
We have 3 data context types:
- Ephemeral Data Context: Exists in memory, and does not persist beyond the current Python session.
- File Data Context: Exists as a folder and configuration files. Its contents persist between Python sessions.
- Cloud Data Context: Supports persistence between Python sessions, but additionally serves as the entry point for Great Expectations Cloud.
We can create an Ephermeral data context as follows:
context = gx.get_context()
# This will create a temporary folder in /tmp to hold the data context files
The output:

We can create a File data context as follows:
from great_expectations.data_context import FileDataContext
context = FileDataContext(context_root_dir = "../services")
# This will create a folder "../services/gx" in the current working directory and will store the data context files
# context = FileDataContext(project_root_dir = "../services")
# This will create a folder "../services/gx" in the current working directory and will store the data context file
if you have an existing file data context, then you can load it as follows:
context = gx.get_context(context_root_dir = "../services/gx")
# OR
# context = gx.get_context(project_root_dir = "../services")
You should work with File data context for the project.
You can convert an Ephemeral Data Context to a Filesystem Data Context.
context = context.convert_to_file_context()
This will put the data context files in a folder ./gx.
Data Sources
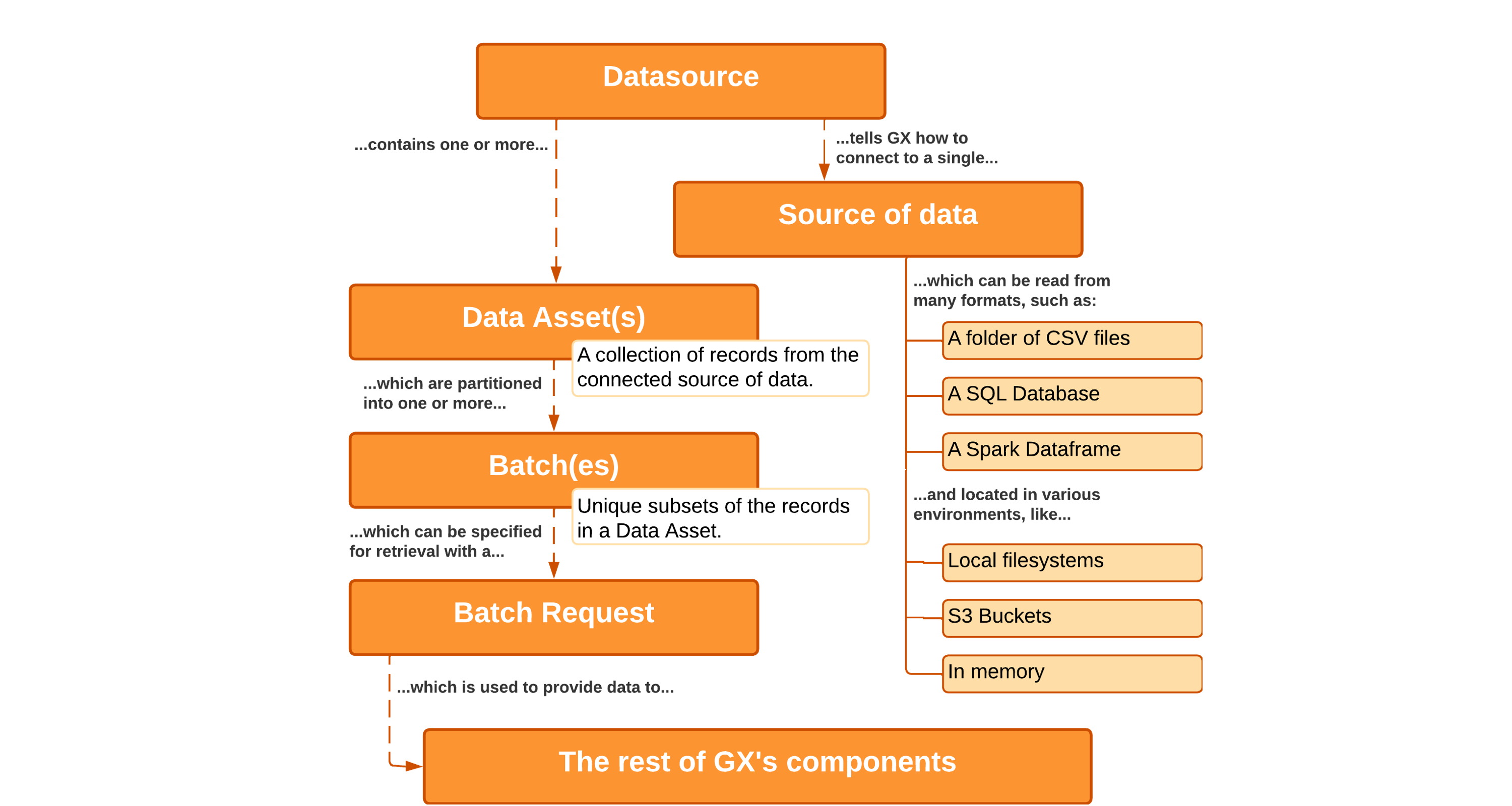
Data Sources connect GX to Data Assets such as CSV files in a folder, a PostgreSQL database hosted on AWS, or any combination of data formats and environments. Regardless of the format of your Data Asset or where it resides, Data Sources provide GX with a unified API for working with it.
Data Sources do not modify your data.
We can use a Filesystem data source or a cloud data source but for this project, we need to use a Filesystem data source.
Single file with pandas
We can create a Pandas data source to connect to the data file stored on the local filesystem as follows:
ds1 = context.sources.add_or_update_pandas(name="my_pandas_ds")
# ds1 is PandasDatasource
Multiple files with pandas
We can create a Pandas data source to connect to the data files stored in a folder on the local filesystem as follows:
ds2 = context.sources.add_or_update_pandas_filesystem(name="my_pandas_ds", base_directory="../data/raw")
# base_directory is the path to the folder containing data files
# ds2 is PandasFilesystemDatasource
Data Assets
Data Assets are collections of records within a Data Source.
- A Data Source tells GX how to connect to your Data Assets
- Data Assets tell GX how to organize that data into batches
Filesystem data assets
We can create a csv data asset to read the data from data file(s) stored on the local filesystem as follows:
# Read a single data file
da1 = ds1.add_csv_asset(
name = "asset01",
filepath_or_buffer="/path/to/data/file.csv"
)
# Read multiple data files
da2 = ds2.add_csv_asset(
name = "asset02",
batching_regex = r"yellow_tripdata_sample_(?P<year>\d{4})-(?P<month>\d{2})\.csv"
)
# Here we defined a regex pattern to read files only those match this pattern
In-memory data assets
Here we will try to read data from a Pandas dataframe residing in memory. So, Pandas is responsible for reading the data and loading to the memory.
import pandas as pd
df = pd.read_csv("/path/to/data/file.csv")
# ds1 is a PandasDatasource
da3 = ds1.add_dataframe_asset(name = "pandas_dataframe")
We did not pass the dataframe so far, we will do when we build a batch request.
Batch and Batch Request
Data Assets can be partitioned into Batches. Batches are unique subsets of records within a Data Asset. For example, say you have a Data Asset in a SQL Data Source that consists of all records from last year in a given table. You could then partition those records into Batches of data that correspond to the records for individual months of that year.
A Batch Request specifies one or more Batches within the Data Asset. Batch Requests are the primary way of retrieving data for use in GX.
From filesystem data assets
We can request data from the previous data asset as follows:
batch_request = da1.build_batch_request()
batches = da1.get_batch_list_from_batch_request(batch_request)
for batch in batches:
print(batch.batch_spec)
From in-memory data assets
Here we will pass the Pandas dataframe to build the batch request.
batch_request = da3.build_batch_request(dataframe = df)
batches = da3.get_batch_list_from_batch_request(batch_request)
for batch in batches:
print(batch.batch_spec)
You can filter data when you build batch requests for data assets connected to a PSQL table or Pandas file system data source. The options to batch requests depends on the type of data assets being used, we can know that as follows:
print(my_asset.batch_request_options)
For instance, for file based data assets, we can use sorters to sort the retrieved data as follows:
my_asset = my_asset.add_sorters(['+year', '-month'])
# Here we can use da2 as data asset
# Here the data will be sorted by `year` in asc order and by `month` in desc order
We can use head() method of the Batch to see the content of the dataframe.
Expectations
Expectations provide a flexible, declarative language for describing expected behaviors. Unlike traditional unit tests which describe the expected behavior of code given a specific input, Expectations apply to the input data itself.
For example, you can define an Expectation that a column contains no null values. When GX runs that Expectation on your data it generates a report which indicates if a null value was found.
Expectations can be built directly from the domain knowledge of subject matter experts, interactively while introspecting a set of data, or through automated tools provided by GX.
How to build expctations
We have four workflows to create expectations. The methodology for saving and testing Expectations is the same for all workflows.
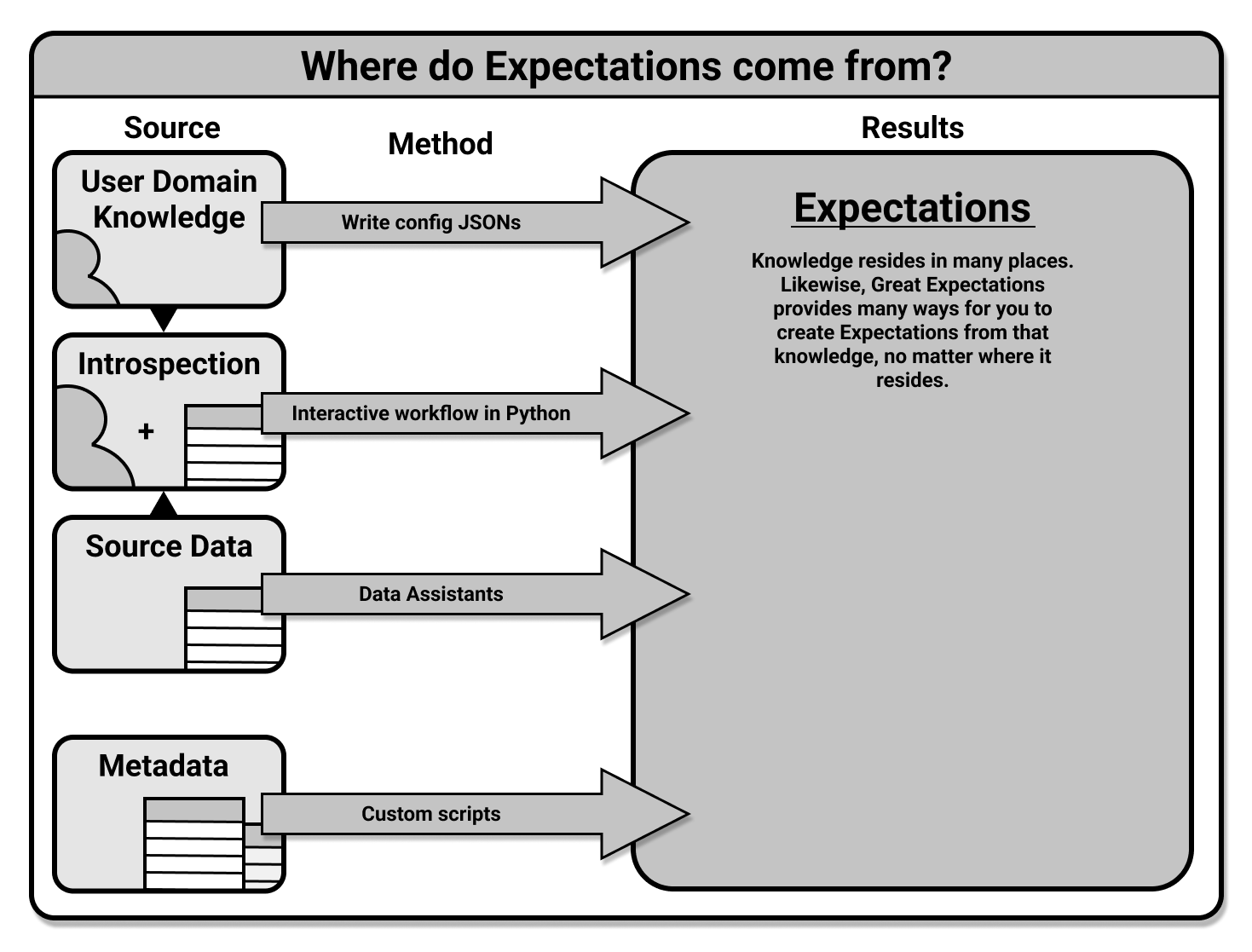
1. Create Expectations interactively
Here, you work in a Python interpreter or Jupyter Notebook.
- You use a Validator and call Expectations as methods on it to define them in an Expectation Suite.
- When you have finished you save that Expectation Suite into your Expectation Store.
Example:
# Create a batch request
data_asset = context.get_datasource("my_datasource").get_asset("my_data_asset")
batch_request = data_asset.build_batch_request()
# Create an expectations suite
context.add_or_update_expectation_suite("my_expectation_suite")
# Verify that the expectation is created
context.list_expectation_suite_names()
# Create a validator
validator = context.get_validator(
batch_request=batch_request,
expectation_suite_name="my_expectation_suite",
)
# Check the validator content
print(validator.head())
# Add your expectations on the validator
validator.expect_column_values_to_not_be_null(
column="vendor_id"
)
validator.expect_column_values_to_not_be_null(
column="account_id"
)
validator.expect_column_values_to_be_in_set(
column="transaction_type",
value_set = ["purchase", "refund", "upgrade"]
)
# Save your expecations suite
validator.save_expectation_suite(
discard_failed_expectations = False
)
# In interactive mode, GX will add all exepctations that you successfully run to the suite.
2. Manually define Expectations
Advanced users can use a manual process to create Expectations. This workflow does not require Data Assets, but it does require knowledge of the configurations available for Expectations.
Example:
# Data assets and batch request are not needed since we will not run the expectations
# data_asset = context.get_datasource("my_datasource").get_asset("my_data_asset")
# batch_request = data_asset.build_batch_request()
# Create an expectations suite
suite = context.add_or_update_expectation_suite("my_expectation_suite")
# Verify that the expectation is created
context.list_expectation_suite_names()
# Import the class to create expectation configuration
from great_expectations.core.expectation_configuration import (
ExpectationConfiguration
)
# Create your expectations
# Expectation 1
expectation_configuration_1 = ExpectationConfiguration(
# Name of expectation type being added
expectation_type="expect_column_values_to_not_be_null",
# These are the arguments of the expectation
# The keys allowed in the dictionary are Parameters and
# Keyword Arguments of this Expectation Type
kwargs={
"column": "vendor_id"
},
# This is how you can optionally add a comment about this expectation.
# It will be rendered in Data Docs.
# See this guide for details:
# `How to add comments to Expectations and display them in Data Docs`.
meta={
"notes": {
"format": "markdown",
"content": "Some clever comment about this expectation. **Markdown** `Supported`",
}
},
)
# Add the Expectation 1 to the suite
suite.add_expectation(
expectation_configuration=expectation_configuration_1
)
# validator.expect_column_values_to_not_be_null(
# column="vendor_id"
# )
# Expectation 2
expectation_configuration_2 = ExpectationConfiguration(
# Name of expectation type being added
expectation_type="expect_column_values_to_not_be_null",
# These are the arguments of the expectation
# The keys allowed in the dictionary are Parameters and
# Keyword Arguments of this Expectation Type
kwargs={
"column": "account_id"
},
# This is how you can optionally add a comment about this expectation.
# It will be rendered in Data Docs.
# See this guide for details:
# `How to add comments to Expectations and display them in Data Docs`.
meta={
"notes": {
"format": "markdown",
"content": "Some clever comment about this expectation. **Markdown** `Supported`",
}
},
)
# Add the Expectation 2 to the suite
suite.add_expectation(
expectation_configuration=expectation_configuration_2
)
# validator.expect_column_values_to_not_be_null(
# column="account_id"
# )
# Expectation 1
expectation_configuration_3 = ExpectationConfiguration(
# Name of expectation type being added
expectation_type="expect_column_values_to_be_in_set",
# These are the arguments of the expectation
# The keys allowed in the dictionary are Parameters and
# Keyword Arguments of this Expectation Type
kwargs={
"column": "transaction_type",
"value_set": ["purchase", "refund", "upgrade"],
},
)
validator.expect_column_values_to_be_in_set(
column="transaction_type",
value_set = ["purchase", "refund", "upgrade"]
)
# Add the Expectation 3 to the suite
suite.add_expectation(
expectation_configuration=expectation_configuration_3
)
# Save your expecations suite
context.save_expectation_suite(expectation_suite=suite)
# validator.save_expectation_suite(
# discard_failed_expectations = False
# )
# In non-interactive mode, you have to manually add each exepctation to the suite.
3. Create Expectations with Data Assistants
Here, you use a Data Assistant to generate Expectations based on the input data you provide. You can preview the Metrics that these Expectations are based on, and you can save the generated Expectations as an Expectation Suite in an Expectation Store.
You can find all supported expectations in the gallery of GX expectations
Expectation Suites
When GX validates data, an Expectation Suite helps streamline the process by running all of the contained Expectations against that data. In almost all cases, when you create an Expectation you will be creating it inside of an Expectation Suite object.
You can define multiple Expectation Suites for the same data to cover different use cases. An example could be having one Expectation Suite for raw data, and a more strict Expectation Suite for that same data post-processing. Because an Expectation Suite is decoupled from a specific source of data, you can apply the same Expectation Suite against multiple, disparate Data Sources. For instance, you can reuse an Expectation Suite that was created around an older set of data to validate the quality of a new set of data.
Data Assistants
A Data Assistant is a utility that automates the process of building Expectations by asking questions about your data, gathering information to describe what is observed, and then presenting Metrics and proposed Expectations based on the answers it has determined. This can accelerate the process of creating Expectations for the provided data.
Data validation workflow in GX
The following diagram illustrates the end-to-end GX OSS data validation workflow that you’ll implement with this quickstart. Click a workflow step to view the related content.

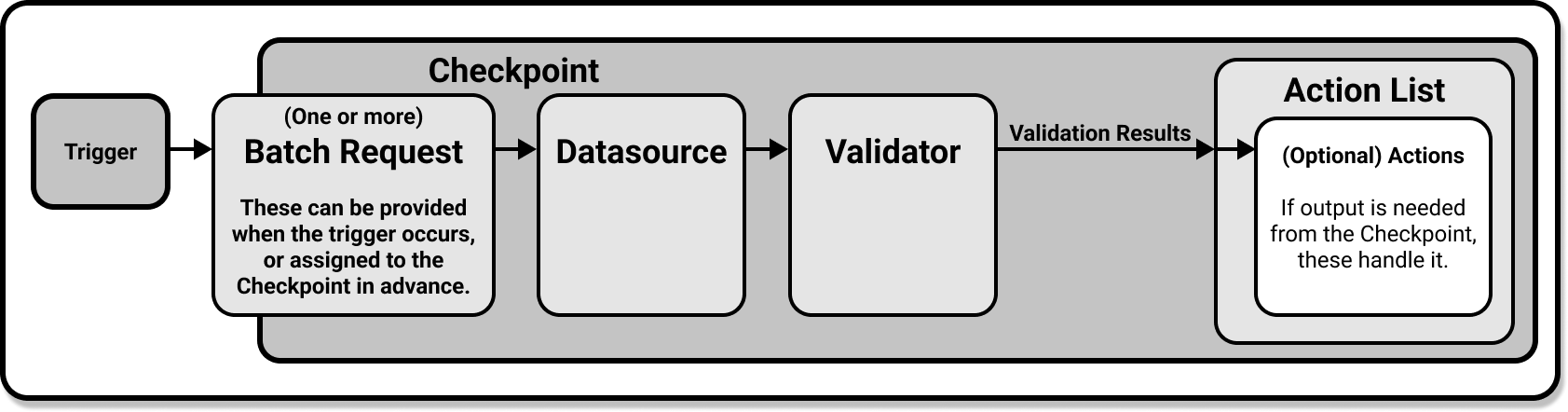
Checkpoints
A Checkpoint is the primary means for validating data in a production deployment of GX. Checkpoints provide an abstraction for bundling a Batch (or Batches) of data with an Expectation Suite (or several), and then running those Expectations against the paired data.
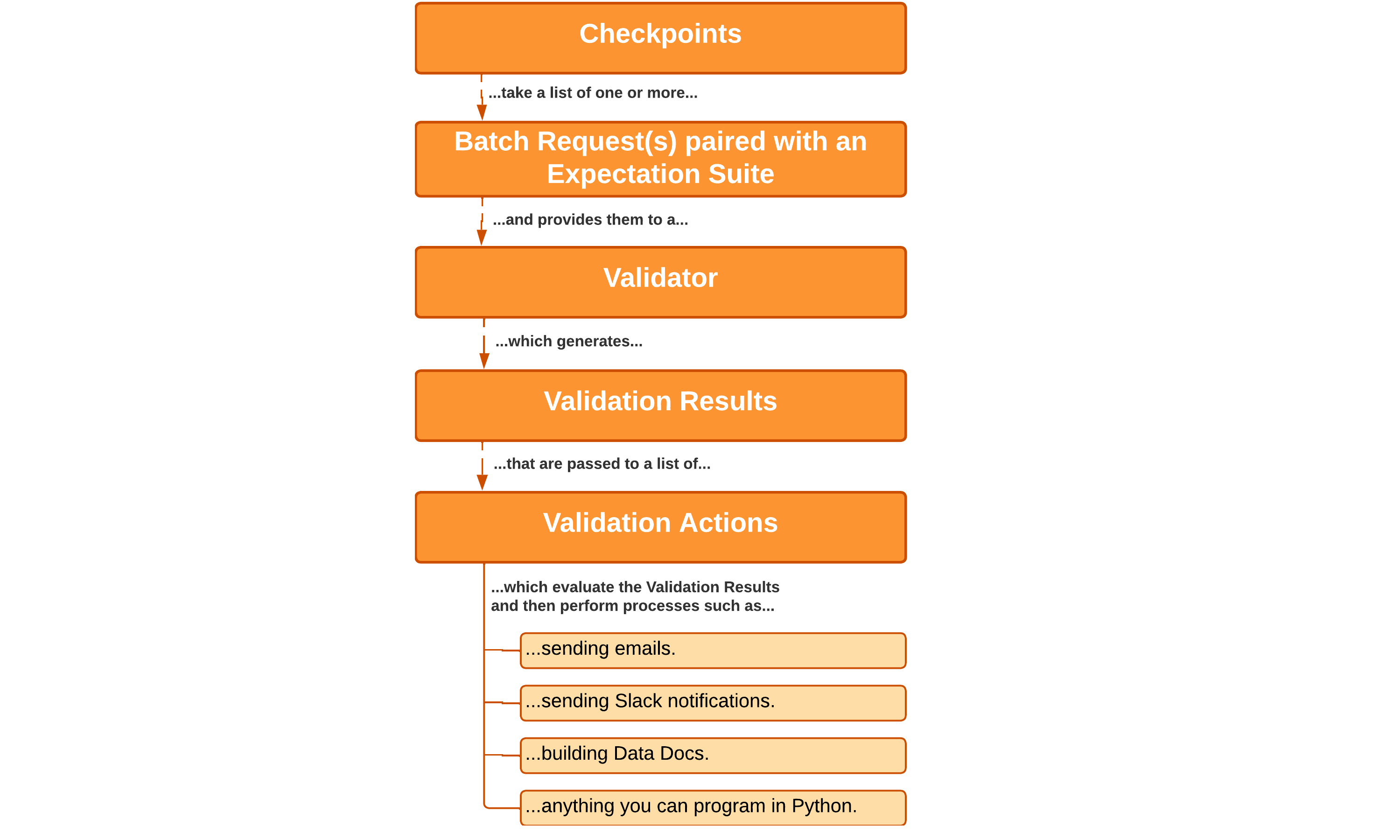
Create a checkpoint
# Given the batch requests and the expectation suites
# We create checkpoint
checkpoint = context.add_or_update_checkpoint(
name="my_checkpoint",
validations=[ # A list of validations
{
"batch_request": batch_request,
"expectation_suite_name": "my_expectation_suite",
},
],
)
Run a checkpoint
checkpoint_result = checkpoint.run()
By default, a Checkpoint only validates the last Batch included in a Batch Request. We can run the checkpoint on all batches in a batch request by converting the list of batches into a list of batch requests 
# Given a batch request
batch_list = asset.get_batch_list_from_batch_request(batch_request)
batch_request_list = [batch.batch_request for batch in batch_list]
validations = [
{
"batch_request": batch.batch_request,
"expectation_suite_name": "my_expectation_suite"
}
for batch in batch_list
]
checkpoint = context.add_or_update_checkpoint(
name="my_validator_checkpoint",
validations=validations
)
checkpoint_result = checkpoint.run()
Present results in data docs
# Build the data docs (website files)
context.build_data_docs()
# Open the data docs in a browser
context.open_data_docs()
Retrieve your Checkpoint
retrieved_checkpoint = context.get_checkpoint(name="my_checkpoint")
We can add more validations (different batch requests with different expectation suites) to the checkpoint as follows:
validations = [
{
"batch_request": {
"datasource_name": "my_datasource",
"data_asset_name": "users",
},
"expectation_suite_name": "users.warning",
},
{
"batch_request": {
"datasource_name": "my_datasource",
"data_asset_name": "users.error",
},
"expectation_suite_name": "users",
},
]
checkpoint = context.add_or_update_checkpoint(
name="my_checkpoint",
validations=validations,
)
Validation Results
The Validation Results returned by GX tell you how your data corresponds to what you expected of it. You can view this information in the Data Docs that are configured in your Data Context. Evaluating your Validation Results helps you identify issues with your data. If the Validation Results show that your data meets your Expectations, you can confidently use it.
Data docs
Data Docs are human-readable documentation generated by GX. Data Docs describe the standards that you expect your data to conform to, and the results of validating your data against those standards. The Data Context manages the storage and retrieval of this information.
We can host and share data docs locally as follows:
# Build the data docs (website files)
context.build_data_docs()
# Open the data docs in a browser
context.open_data_docs()
The output:

Actions
The Validation Results generated when a Checkpoint runs determine what Actions are performed. Typical use cases include sending email, Slack messages, or custom notifications. Another common use case is updating Data Docs sites. Actions can be used to do anything you are capable of programming in Python. Actions are a versatile tool for integrating Checkpoints in your pipeline’s workflow.
In the project, we will raise an exception if there are any failed expectations. You can get the status of the checkpoint as follows:
checkpoint_result.success
Demo
- Follow this notebook
A script to run the checkpoint
After you define your checkpoint and expectations suite. You should write a script/function to validate your data.
import great_expectations as gx
context = gx.get_context(project_root_dir = "services")
retrieved_checkpoint = context.get_checkpoint(name="my_checkpoint")
results = retrieved_checkpoint.run()
assert results.success
great_expectations CLI
Great Expectations comes with a CLI to perform operations as command lines. This tool will basically create a FileDataContext in a folder gx in the current working directory.
It is not recommended to use the CLI to create datasources or other objects. Use this tool only if you want to explore the GX project folder. Use the Python API (great_expectations) to do tasks with GX.
Some commands:
- Initialize a GX project
great_expectations init
You initialize your project only once per repository. init initializes a new Great Expectations project gx in the current working directory. If you want to specify the GX project directory then you need to Access the folder “project_root_dir” where gx folder will be created by the CLI and run the command line.

- List all data sources
great_expectations datasource list
This will guide you to create a datasource and then opens a Jupyter notebook. You run the cells to create a new data source.
- build data docs
great_expectations docs build
Where you should use it?
You should validate the data after you collect it and whenever you transform it. You can see in the figure below that the data validation happens after:
- Collecting and ingesting the data to a data store/warehouse
- Cleaning the data
- Data engineering
- Model prediction
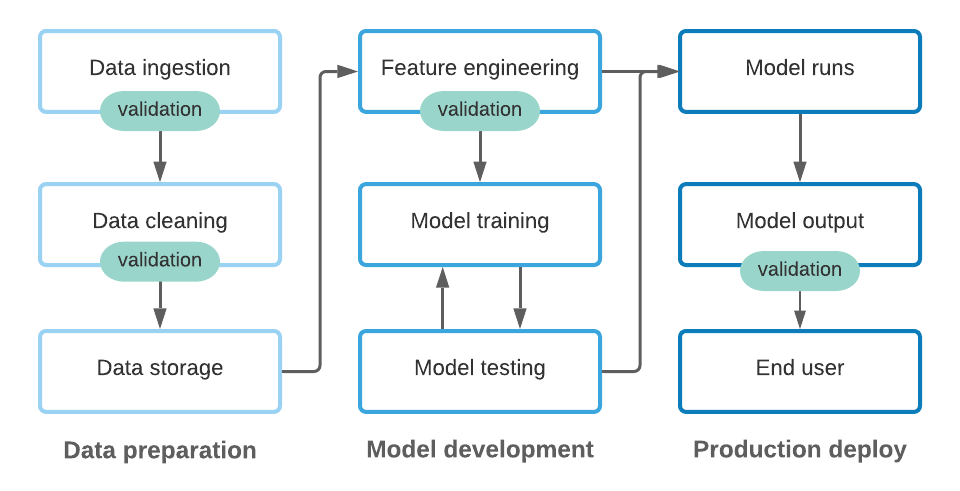
In this project, you will validate the data:
- After you collect it where you need to define data requirements (expectations) and test quality of the data. This will ensure that the data from the source is valid. The valid data will be stored in a Postgresql database.
- After you transform it, exactly after data engineering/preparation and before storing features in feature stores. This will ensure tha the data is valid before training the model. The valid data will be stored in a feature store.
Data Quality
Data quality (DQ) is defined as the data’s suitability for a user’s defined purpose. It is subjective, as the concept of quality is relative to the standards defined by the end users’ expectations.
Data Quality Expectations: It is possible that for the exact same data, depending on their usage, different users can have totally different data quality expectations. For example, the accounting department needs accurate data to the penny, whereas the marketing team does not, because the approximate sales number are enough to determine the sales trends.
What are the Six Data Quality Dimensions?
The six primary data quality dimensions are Accuracy, Completeness, Consistency, Uniqueness, Timeliness, and Validity. However, this classification is not universally agreed upon.

Completeness
The completeness data quality dimension is defined as the percentage of data populated vs. the possibility of 100% fulfillment.
- Example on GX expectation:
expect_column_values_to_not_be_null— expect the column values to not be null.- It is labeled as “Missingness” in the GX gallery of Expectations.
Uniqueness
Uniqueness is a dimension of data quality that refers to the degree to which each record in a dataset represents a unique and distinct entity or event. It measures whether the data is free of duplicates or redundant records, and whether each record represents a unique and distinct entity.
- Example on GX expectation:
expect_column_values_to_be_unique— Expect each column value to be unique.- It is labeled as “Cardinality” in the GX gallery of Expectations.
Timelessness
Timelessness is a dimension of data quality that measures the relevance and accuracy of data over time. It refers to whether the data is up to date.
- Example on GX expectation:
expect_column_values_to_be_between— expect the column values to not be null.- It is labeled as “Sets” in the GX gallery of Expectations.
Validity
Validity is a dimension of data quality that measures whether the data is accurate and conforms to the expected format or structure. Because invalid data can disrupt the training of AI algorithms on a dataset, organizations should establish a set of methodical business rules for evaluating data validity.
- Example on GX expectation:
expect_column_values_to_match_regex— expect the column values to match a specific regex format.- It is labeled as (“Schema”) in the GX gallery of Expectations.
Accuracy
Accuracy is the degree to which data represent real-world things, events, or an agreed-upon source.
- Example on GX expectation:
expect_column_max_to_be_between— expect the column max value to between a range of two specific values.- It is labeled as (“Numerical data”) in the GX gallery of Expectations.
Consistency
Consistency is a dimension of data quality that refers to the degree to which data is uniform across a dataset.
- Example on GX expectation:
expect_column_values_to_be_between— expect each column value to be in a given set.- It is labeled as (“Set”) in the GX gallery of Expectations.
More than one data quality dimension can be checked using one GX expectation. There are more than one expectation to check each data quality dimension.
Project tasks
Note: The project tasks are graded, and they form the practice part of the course. We have tasks for repository and as well as for report (for Master’s student).
A. Repository
- Create a Github repo for the project. Use the Github UI, select Python for
.gitignoreand add aREADME.mdfile. Add the instructor and all team members to the repository as contributors. The strcture is similar to:
├───README.md # Repo docs
├───.gitignore # gitignore file
├───requirements.txt # Python packages
├───configs # Hydra configuration management
├───data # All data
├───docs # Project docs like reports or figures
├───models # ML models
├───notebooks # Jupyter notebooks
├───outputs # Outputs of Hydra
├───pipelines # A Soft link to DAGs of Apache Airflow
├───reports # Generated reports
├───scripts # Shell scripts (.sh)
├───services # Metadata of services (PostgreSQL, Feast, Apache airflow, ...etc)
├───sql # SQL files
├───src # Python scripts
└───tests # Scripts for testing Python code
Note: You can use Cookiecutter PyPackage if you prefer but it is not required in this project.
2. Install VS Code and add required and useful extensions such as Python, Docker, Jupyter, …etc.
3. Open the project repository using VS Code in some local folder.
4. Create a virtual environment using venv or conda. Activate it.
5. Add requirements.txt. Add an executable file like a script scripts/install_requirements.sh to install the requirements using the pip to the created virtual environment. Run it whenever you added a new package to requirements.txt.
6. Complete the notebook business_understanding.ipynb(shared in this document) and push it to notebooks folder. You can complete this notebook by writing on the notebook itslef or by writing it in a document shared as pdf and pushed to reports folder. Build the ML Canvas and push it to reports folder as a pdf.
7. Use Jupyter/Colab notebooks to understand the data. The notebook should include data analysis results supported with charts as follows:
- Data Description and exploration:
- What data features need to be cleaned
- What cleaning methods you applied to get a clean data
- The description of the data
- The quantity of the data
- The data types of the features
- How many unique values per feature
- Categories of feature types (which features are categorical, which are numerical, which are text, …)
- This needs to be clearly stated and not based on the datatype of the features since it can be misleading. You need to read the data description and understand each feature.
- The distribution of each data feature and the target
- Using charts, analyse visually the linear relationship of each feature with the target (Bivariate analysis). You can also do that between features.
- Make a conclusion (Are there linear relationships between them?)
- Initially, decide which ML methods could be useful/not useful for this data
- Try to form a preliminary set of features which have relationships and you believe may contribute to the performance of the ML model
- Data transformation methods for ML-ready datasets
- Which data features need transformation
- What type of transformation needed per feature (e.g. one hot encoding for categorical features)
- Do a preliminary data transformation to get an ML-ready data
- Correlation analysis (Only Master’s students)
- Which features are correlated
- Which features have strong correlation with the target.
- Which correlation methods you used and why?
- Data quality verification
- Missing values
- How many missing values are there per feature
- Which features need to be imputed/handled
- How you will handle the missing features
- What is the quality of the data (bad, good, excellent)
- Do a preliminary data cleaning to get a data without missing values
- Missing values
- Data requirements:
- Data validation/testing
- Write expectations using GX about the data coming from the source
- Validate the expectations
- Data validation/testing
- Do a preliminary ML modeling in the Jupyter notebook. Build a proof-of-concept (POC) ML model.
- Add all notebooks to the folder
notebooks. - Keep the repository organized and well-documented. Add README files to each folder and documentation to source code files (Use Pylint extension of VS Code)
- Add a new branch (e.g.
dev) to the repo. - Add a function
sample_datain a modulesrc/data.pyto read the data file and take a sample. Use Hydra to manage the data url in the configs and any configurations needed like the size of the sample, the name of the dataset,…etc. You need to define a structure for project configurations and use Hydra to read them from the source code. The function should read the data url from config files using Hydra and sample the data. Then, it stores the data samples indata/samplesfolder assample.csvwhere the sample size is 20% of the total rows in the whole data. The sample size can be added to the config files too. The idea here is to make your project maintainable and ready for any changes with minimal modifications (DRY principle). For each new sample added, version the data usingdvcto not lose any data samples. - Run the function
sample_dataand it should generate a sample. The function should overwrite the filesample.csvif it already exists. You can manage the data versions usingdvc. - Add test functions (at least 2) in the
testsfolder to test the functionsample_dataand make sure it can pass all tests. You can add extensions from VS Code to setuppytest. - Add another function
validate_initial_datawhich declares expectations about the data features and validates them. Create an expectation suite and save them. Make sure that you created a File data context in a folderservices/gxwhere the metdata of the context will be stored.
Note: You need to write expectations to satisfy the data requirements. The data requirements should be written (and added to 1_business_data_understanding.ipynb) to cover the data quality dimensions which are completeness, uniqueness, timelessness, validity, consistency, and accuracy. Basically, the number of expectations is not a fixed number. Ideally, for each data feature we aim to validate all dimensions. For simplicity, we ask to validate 3 most important dimensions for each of the 7 most critical features (in total 21-40 expectations). Do not try to validate same dimension for all features, use a diverse set of quality dimensions. You should validate each dimension at least once per dataset.
Note: If any of the expectations got failed, then the program should raise a custom exception (alert) and terminate the program. This is the action that we will use for validating the data.
16. Write a script scripts/test_data.sh to automate:
- Take a data sample
- Validate the data sample
- Version the data sample
Note: You should not version the data if it is invalid.
Note: Make sure that it is automated and it gives reproducible results without side effects.
17. Commit the changes to dev branch and merge it to main branch.
18. You should commit and push whenever you fixed some issue or started/finished building some artifact.
Use properly all tools (hydra, pytest, dvc, …etc) that you studided in this phase.
B. Report [Only for Master’s students]
Complete the following chapters:
-
Chapter 1: Introduction
- Write a short introduction for your report. Add some motivational statements to your case study. Add some figures or statistics to support your arguments.
-
Chapter 2: Business and Data understanding
-
This phase focuses on understanding the project objectives and requirements from a business perspective, then converting this knowledge into a machine learning problem. Your organisation may have competing objectives and constraints that must be properly balanced. The goal of this stage of the process is to uncover important factors that could influence the outcome of the project. Neglecting this step can mean that a great deal of effort is put into producing the right answers to the wrong questions.
-
Write a paragraph to state your business problem connected to your data, assessment of the current situation. Give the reader a short overview of the problem and the necessary background about the business that you will focus on in your report. Make sure that concepts are explained/defined. Do not forget to cite your sources.
-
Section 2.1. Terminology
- Compile a glossary of terminology relevant to the project. This will generally have two components:
- Section 2.1.1. Business terminology A glossary of relevant business terminology, which forms part of the business understanding available to the project. Constructing this glossary is a useful “knowledge elicitation” and education exercise.
- Section 2.1.2. ML terminology A glossary of machine learning terminology, illustrated with examples relevant to the business problem in question.
- Compile a glossary of terminology relevant to the project. This will generally have two components:
-
Section 2.2. Scope of the ML project
- Section 2.2.1. Background Write here the information that is known about the organization’s business situation at the beginning of the project.
- Section 2.2.2. Business problem State here the business problem.
- Section 2.2.3. Business objectives State here the project objectives based on the business objectives. This means describing your primary objective from a business perspective. There may also be other related questions that you would like to address. For example, your primary goal might be to keep current customers by predicting when they are prone to move to a competitor. Related business questions might be “Does the channel used affect whether customers stay or go?” or “Will lower ATM fees significantly reduce the number of high-value customers who leave?”.
- Section 2.2.4. ML objectives A business goal states objectives in business terminology. A machine learning goal states project objectives in technical terms. For example, the business goal might be “Increase catalogue sales to existing customers.” A machine learning goal might be “Predict how many widgets a customer will buy, given their purchases over the past three years, demographic information (age, salary, city, etc.), and the price of the item.”
-
Section 2.3. Success criteria
- Specify the success criteria of the ML project on three different levels: the business success criteria, the ML success criteria and the economic success criteria. Make sure that the success criteria are measurable and defined in alignment to each other and with respect to the overall system requirements to prevent contradictory objectives.
- Section 2.3.1. Business Success Criteria: Define the purpose and the success criteria of the ML application from a business point of view. For example, if an ML application is planned for a quality check in production and is supposed to outperform the current manual failure rate of 3%, the business success criterion could be derived as e.g. “failure rate less than 3%”.
- Section 2.3.2. ML Success Criteria: Translate the business objective into ML success criteria (see table 2). It is advised to define a minimum acceptable level of performance to meet the business goals (e.g. for a Minimal Viable Product (MVP)) In the mentioned example, the minimal success criterion is defined as “accuracy greater 97%”, but data scientists might optimize further, for example, the true-positive rate to miss items with quality issues.
- Section 2.3.3. Economic Success Criteria: It is best practice to add an economic success criterion in the form of a Key Performance Indicator (KPI) to the project. A KPI is an economical measure for the relevance of the ML application. In the mentioned example, a KPI can be defined as “cost savings with automated quality check per part”.
-
Section 2.5. Data collection
- This section should include the initial exploration of the metadata of the dataset. It should provide reports about data collection, data version control.
- Section 2.5.1 Data collection report: Specify the data source from which the data is collected, the format and data types of data features, the quantity of the data, and how the data is collected.
- Section 2.5.2 Data version control report: Describe data versions, what change happend in the data, how do you backup the data, how do you store historical data, and which people who have access and can modify the data. This should be done after you collect the data.
-
Section 2.6. Data quality verification
- Here, we explore the data and check the quality. We need to define expectations for the data and validate the data.
- Section 2.6.1. Data description: A section to describe the data that has been acquired including its format, its quantity (for example, the number of records and fields in each table), the identities of the fields and any other surface features which have been discovered.
- Section 2.6.2. Data exploration present results of your data exploration, including first findings or initial hypothesis and their impact on the remainder of the project. If appropriate you could include graphs and plots here to indicate data characteristics that suggest further examination of interesting data subsets.
- Section 2.6.3. Data requirements describe the data requirements. The requirements can be defined either on the meta-level or directly in the data, and should state the expected conditions of the data, i.e., whether a certain sample is plausible. The requirements can be, e.g., the expected feature values (a range for continuous features or a list for discrete features), the format of the data and the maximum number of missing values. The bounds of the requirements has to be defined carefully to include all possible real world values but discard non-plausible data. Data that does not satisfy the expected conditions could be treated as anomalies and need to be evaluated manually or excluded automatically. To mitigate the risk of anchoring bias in this first phase discussing the requirements with a domain expert is advised. Documentation of the data requirements could be expressed in the form of a schema with strict data types and conditions.
- Section 2.6.4. Data quality verification report verify and report the quality of the data. Examine the quality of the data, addressing questions such as:
- Is the data complete (does it cover all the cases required)?
- Is it correct, or does it contain errors and, if there are errors, how common are they?
- Are there missing values in the data? If so, how are they represented, where do they occur, and how common are they?
-
Section 2.7. Project feasibility
- Same requirements as in the colab notebook.
-
Section 2.8. Project plan
- Same requirements as in the colab notebook.
-
-
Push your report as pdf to
reportsfolder for this phase. Add a version to the report such asreportv1.pdf.
References
- Case study - Machine Learning for Feeling Analysis in Twitter Communications: A Case Study in HEYDRU!, Perú
- CRISP-ML(Q). The ML Lifecycle Process
- Model Cards for Model Reporting
- MACHINE LEARNING CANVAS
- An introduction to CRISP-DM
- The big book of MLOps
- MLOps - Google Cloud
- What is MLOps
- Python Testing with pytest - 2nd edition
- How does Great Expectations fit into ML Ops?
- Getting started with Great Expectations
- 6 Dimensions of Data Quality, Examples, and Measurement