Lab 4 - Apache Hadoop HDFS
Course: Big Data - IU S25
Author: Firas Jolha
Agenda
Prerequisites
- Installed Docker and Docker compose
- Experience with HDFS
- Background in Hadoop and its components
Objectives
- Install Hadoop
- Setup multi-node cluster of HDFS nodes
- Setup HDFS components
- Hadoop HDFS configuration
Introduction
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
Here we will discuss the core components of Hadoop, namely the Hadoop Distributed File System (HDFS), Yet Another Resource Negotiator (YARN) and next lab we will discucss MapReduce framework.
Hadoop HDFS
The Hadoop Distributed File System (HDFS) is highly fault-tolerant and is designed to be deployed on low-cost hardware. HDFS provides high throughput access to application data and is suitable for applications that have large data sets. HDFS is part of the Apache Hadoop Core project.
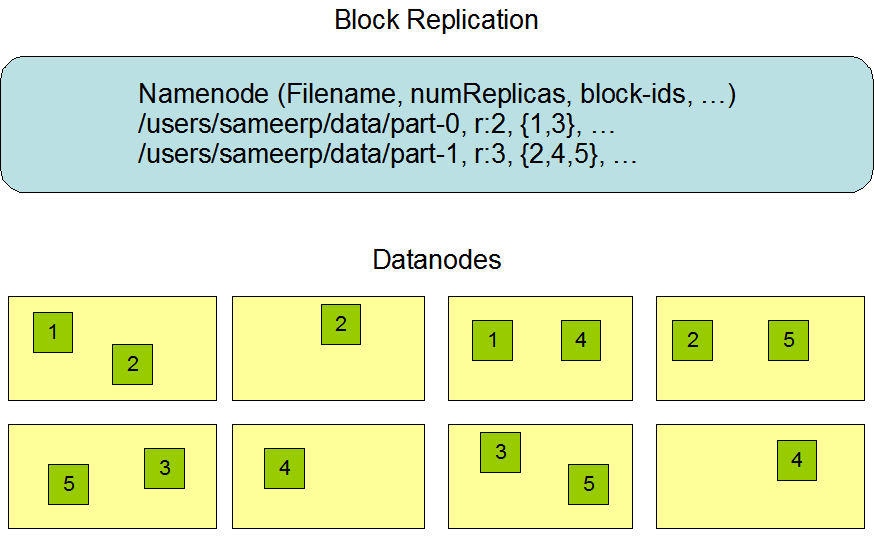
HDFS is a software-based filesystem implemented in Java and it sits on top of the native filesystem. The main concept behind HDFS is that it divides a file into blocks (typically 128 MB) instead of dealing with a file as a whole. This allows many features such as distribution, replication, failure recovery, and more importantly distributed processing of the blocks using multiple machines. For a 1 GB file with 128 MB blocks, there will be (1024 MB/128 MB) equal to eight blocks. If you consider a replication factor of three, this makes it 24 blocks.
HDFS provides a distributed storage system with fault tolerance and failure recovery. HDFS has two main components: the NameNode and the DataNode.
NameNode and DataNodes
HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients. In addition, there are a number of DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on. HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes.
The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. The DataNodes are responsible for serving read and write requests from the file system’s clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.

The NameNode and DataNode are pieces of software designed to run on commodity machines. These machines typically run a GNU/Linux operating system (OS). HDFS is built using the Java language; any machine that supports Java can run the NameNode or the DataNode software. Usage of the highly portable Java language means that HDFS can be deployed on a wide range of machines. A typical deployment has a dedicated machine that runs only the NameNode software. Each of the other machines in the cluster runs one instance of the DataNode software. The architecture does not preclude running multiple DataNodes on the same machine but in a real deployment that is rarely the case.
The existence of a single NameNode in a cluster greatly simplifies the architecture of the system. The NameNode is the arbitrator and repository for all HDFS metadata. The system is designed in such a way that user data never flows through the NameNode.
HDFS supports a traditional hierarchical file organization. A user or an application can create directories and store files inside these directories. The file system namespace hierarchy is similar to most other existing file systems; one can create and remove files, move a file from one directory to another, or rename a file. HDFS supports user quotas and access permissions. HDFS does not support hard links or soft links.
The NameNode maintains the file system namespace. Any change to the file system namespace or its properties is recorded by the NameNode. An application can specify the number of replicas of a file that should be maintained by HDFS. The number of copies of a file is called the replication factor of that file. This information is stored by the NameNode.
HDFS stores each file as a sequence of blocks. The blocks of a file are replicated for fault tolerance.
The HDFS namespace, containing file system metadata, is stored in the NameNode. Every change in the file system metadata is recorded in an EditLog, which persists transactions like file creations. The EditLog is stored in the local file system. The entire file system namespace, including block-to-file mapping and attributes, is stored in a file called FsImage. This file is also saved in the local file system where the NameNode resides. The Checkpoint process involves reading the FsImage and EditLog from disk at NameNode startup. All transactions in the EditLog are applied to the in-memory FsImage, which is then saved back to disk for persistence. After this process, the old EditLog can be truncated.
Setup Hadoop HDFS
You can setup your Hadoop cluster in one of the two supported modes for distributed clusters:
- Pseudo-distributed mode: Here Hadoop will run on a single-node where each Hadoop daemon runs in a separate Java process.
- Fully-Distributed mode: Here Hadoop will run on multiple machines where each machine will host one or more of the Hadoop components.
1. Pseudo-distributed mode
You can run a single node of Apache Hadoop using Docker as follows (pseudo-distributed mode).
- Pull a Linux image such as Ubuntu 20.04 and setup this image with ssh access.
docker pull ubuntu:20.04
# Dockerfile
# Use the official image as a parent image
FROM ubuntu:20.04
# Update the system, install OpenSSH Server, and set up users
RUN apt-get update && apt-get upgrade -y && \
apt-get install -y openssh-server
# Create user and set password for user and root user
RUN useradd -rm -d /home/ubuntu -s /bin/bash -g root -G sudo -u 1000 ubuntu && \
echo 'root:root' | chpasswd
# Set up configuration for SSH
RUN mkdir /var/run/sshd && \
sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config && \
sed 's@session\s*required\s*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd && \
echo "export VISIBLE=now" >> /etc/profile
# Expose the SSH port
EXPOSE 22
# Run SSH
CMD ["/usr/sbin/sshd", "-D"]
And build it.
docker build -t ubuntu-ssh .
- Run a container and access it.
docker run --name hadoop_single_node \
-p 8088:8088 \
-p 8080:8080 \
-p 8042:8042 \
-p 4040:4040 \
-p 4041:4041 \
-p 9000:9000 \
-p 9870:9870 \
-p 9868:9868 \
-p 19888:19888 \
-itd ubuntu-ssh
docker exec -it hadoop_single_node bash
This will run a docker container from Ubuntu image and all these ports are published such that we can access the services of Hadoop.
- Install Java 8, openssh server and any other packages you prefer.
apt-get update && apt-get -y dist-upgrade && apt-get install -y openssh-server wget openjdk-8-jdk vim && apt-get -y update
- Set JAVA_HOME environment variable.
echo "export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64" >> /etc/profile
source /etc/profile
- Download Hadoop
wget -O /hadoop.tar.gz http://archive.apache.org/dist/hadoop/core/hadoop-3.3.1/hadoop-3.3.1.tar.gz
- Unzip it and store it in somewhere (we will call it hadoop home directory)
tar xfz hadoop.tar.gz
mv /hadoop-3.3.1 /usr/local/hadoop
rm /hadoop.tar.gz
- Set Hadoop home directory.
echo "export HADOOP_HOME=/usr/local/hadoop" >> /etc/profile
source /etc/profile
- Add Hadoop binaries to system PATH.
echo "export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin" >> /etc/profile
source /etc/profile
- Create directories for storing data in the namenode and datanodes.
mkdir -p $HADOOP_HOME/hdfs/namenode
mkdir -p $HADOOP_HOME/hdfs/datanode
- Configuring Hadoop
<!-- $HADOOP_HOME/etc/hadoop/core-site.xml -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
<!-- $HADOOP_HOME/etc/hadoop/hdfs-site.xml -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
- Check that you can ssh to the localhost without a passphrase.
ssh localhost
If you cannot ssh to localhost without a passphrase, execute the following commands:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
Also add the following to ~/.shh/config file.
Host *
StrictHostKeyChecking no
UserKnownHostsFile /dev/null
LogLevel ERROR
And the following to the file $HADOOP_HOME/etc/hadoop/hadoop-env.sh.
export HADOOP_SSH_OPTS="-o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no"
- Specify configuration for Hadoop binaries in the file (
$HADOOP_HOME/etc/hadoop/hadoop-env.sh).
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
# Make sure that you defined a username for services.
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
export HADOOP_SSH_OPTS="-o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no"
- Format the HDFS file system (only for the first time installation). This will delete everything in HDFS.
hdfs namenode -format
- Start NameNode daemon and DataNode daemon
start-dfs.sh
The hadoop daemon log output is written to the $HADOOP_LOG_DIR directory (defaults to $HADOOP_HOME/logs).
15. Browse the web interface for the NameNode; by default it is available at:
- NameNode - http://localhost:9870/
- Test some HDFS commands.
hdfs fsck /
- When you are done, stop HDFS daemons.
stop-dfs.sh
2. Fully-distributed mode
Here I will run hadoop on a cluster of Docker containers. I will share here the repository where you can clone it to setup hadoop hdfs.
- Clone the repository https://github.com/firas-jolha/docker-spark-yarn-cluster.
mkdir -p ~/spark-test && cd ~/spark-test
git clone https://github.com/firas-jolha/docker-spark-yarn-cluster.git
cd docker-spark-yarn-cluster
Explore the files before you execute any scripts.
2. Run the script startHadoopCluster.sh
bash startHadoopCluster.sh <N>
# N is the number of datanodes to run
This will create
3. Access the cluster-master node and try to check if all services are running.
docker exec -it cluster-master bash
jps -lm
- When you are done. You can run the script
remove_containers.sh(CAUTION) which will remove all containers whose name containscluster. Be careful, if you have any containers that containsclusterin its name, will also be removed.
bash remove_containers.sh
Hadoop HDFS Configuration
Hadoop’s Java configuration is driven by two types of important configuration files:
- Read-only default configuration -
core-default.xml,hdfs-default.xml,yarn-default.xmlandmapred-default.xml. - Site-specific configuration -
etc/hadoop/core-site.xml,etc/hadoop/hdfs-site.xml,etc/hadoop/yarn-site.xmlandetc/hadoop/mapred-site.xml.
These configuration files are .xml files and they have the following structure:
<configuration>
<property>
<name>name1</name>
<value>value1</value>
<description>description1</description>
</property>
<property>
<name>name2</name>
<value>value2</value>
<description>description2</description>
</property>
.
.
.
</configuration>
Additionally, you can control the Hadoop scripts found in the bin/ directory of the distribution, by setting site-specific values via the etc/hadoop/hadoop-env.sh and etc/hadoop/yarn-env.sh.
After you modify the configuration files, you need to restart HDFS components as follows:
stop-dfs.sh
start-dfs.sh
core-site.xml
This file holds the core settings related to Hadoop components. Some of the properties are:
| property | default value | description |
|---|---|---|
| fs.defaultFS | file:/// | The name of the default file system. |
| io.file.buffer.size | 4096 | The size of buffer for use in sequence files. It determines how much data is buffered during read and write operations. |
You can find the description of each of the options provided by Hadoop HDFS and also the default values of theses options from this reference.
hdfs-site.xml
The file configures Hadoop HDFS. You can find it in ($HADOOP_HOME/etc/hadoop/hdfs-site.xml). Some of the properties are:
| property | default | description |
|---|---|---|
| dfs.blocksize | 134217728 | The default block size for new files, in bytes (128k, 512m, 1g, etc.) |
| dfs.replication | 3 | Default block replication |
| dfs.namenode.name.dir | file://${hadoop.tmp.dir}/dfs/name | Determines where on the local filesystem the DFS name node should store the name table(fsimage). |
| dfs.datanode.data.dir | file://${hadoop.tmp.dir}/dfs/data | Determines where on the local filesystem an DFS data node should store its blocks. |
| dfs.webhdfs.enabled | true | Enable WebHDFS (REST API) in Namenodes and Datanodes. |
| dfs.user.home.dir.prefix | /user | The directory to prepend to user name to get the user’s home direcotry. |
| dfs.permissions.enabled | true | If “true”, enable permission checking in HDFS. If “false”, permission checking is turned off, but all other behavior is unchanged. |
You can check here for all available properties with description.
Hadoop HDFS commands
Hadoop HDFS provides a set of commands to manage the files in the file system and also to manage the HDFS components.
DFS
Allows to run a filesystem command on the file system supported in Hadoop. The list of commands supported are available in the official website. You can check below some examples:

- Change the access permission of a file.
hdfs dfs -chmod go-rwx -R /
The -R option will make the change recursively through the directory structure.
- Change the replication factor for a file.
hdfs dfs -setrep 3 /README.txt
This will set the replication factor to 3 replicas only for this file. To change the default replication factor for newly added files, you need to update the property dfs.replication in hdfs-site.xml file.
Check this reference (https://hadoop.apache.org/docs/r3.3.1/hadoop-project-dist/hadoop-common/FileSystemShell.html) for more options of this command.
DFSAdmin
The DFSAdmin command set is used for administering an HDFS cluster. These are commands that are used only by an HDFS administrator.
- Put the cluster in safe mode
hdfs dfsadmin -safemode enter
# hdfs dfsadmin -safemode leave
Safe mode is a Namenode state in which it:
- does not accept changes to the name space (read-only)
- does not replicate or delete blocks.
Safe mode is entered automatically at Namenode startup, and leaves safe mode automatically when the configured minimum percentage of blocks satisfies the minimum replication condition. If Namenode detects any anomaly then it will linger in safe mode till that issue is resolved.
2. Generate a report of avilable datanodes
hdfs dfsadmin -report
- Recommission or decommission data nodes
hdfs dfsadmin -refreshNodes
- Runs the HDFS filesystem checking utility. (it is not dfsadmin command)
hdfs fsck <path>
hdfs fsck /
- Check the locations of file blocks (it is not dfsadmin command)
hdfs fsck /README.txt -files -blocks -locations