Lab 2 - Data Retrieval with SQL and Cypher
Course: Big Data - IU S25
Author: Firas Jolha
Dataset
Agenda
- Lab 2 - Data Retrieval with SQL and Cypher
- Dataset
- Agenda
- Prerequisites
- Objectives
- Introduction
- Dataset Descripion
- Access PostgreSQL server
- PostgreSQL Meta-commands
- Build the Database
- Data Retrieval using SQL
- Graph databases
- Cypher
- Data Retrieval with Cypher
- Common issues
- References
Prerequisites
- HDP Sandbox is installed
- Familiarity with SQL
Objectives
- Access
PostgreSQLdatabase server - Review CRUD operations on a relational database
- Install Neo4j on HDP Sandbox
- Perform some CRUD operations on a graph database
Introduction
The Structured Query Language (SQL) is the most extensively used database language. SQL is composed of a data definition language (DDL), which allows the specification of database schemas; a data manipulation language (DML), which supports operations to retrieve, store, modify and delete data. In this lab, we will practice how to retrieve structured data from relational databases using SQL. Then we will build a graph for the same dataset on Neo4j and return connected data via Cypher queries.
Dataset Descripion
This dataset contains four tables about social media users.
- users. csv contains data about the users of the social net.
- friends.csv contains data about their friendship status
- posts.csv contains data about the posts they made
| File name | Description | Fields |
|---|---|---|
| users.csv | A line is added to this file when a user is subscribed to the socia media along with the age and subscription date time | userid, surname, name, age, timestamp |
| posts.csv | The user can add multiple posts and for each post we have post type and post unix timestamp | postid, user, posttype, posttimestamp |
| friends.csv | The user can have friends and this relationship is mutual | friend1, friend2 |
Access PostgreSQL server
In fact, HDP Sandbox comes with a pre-installed PostgreSQL server so you do not to install any additional software to use PostgreSQL. You can access it via psql as postgres user:
[root@sandbox-hdp ~]# psql -U postgres
This will open a CLI to interact with PostgreSQL. You can access the databases using \c command and the tables via \dt command. For example, you can access the database ambari (a default database on HDP Sandbox) by running the following command in postgreSQL CLI.
postgres=# \c ambari
You are now connected to database "ambari" as user "postgres".
The version of PostgreSQL in HDP 2.6.5 is 9.2.23 as shown below. So you should read the documentation for this version of PostgreSQL.

PostgreSQL Meta-commands
Anything you enter in psql that begins with an unquoted backslash is a psql meta-command that is processed by psql itself. These commands make psql more useful for administration or scripting. Meta-commands are often called slash or backslash commands.
- Switch connection to a new database
dbnameas a userusername
\c <dbname> <username>
- List available databases
\l
- List available tables
\dt
- Describe a table
<table_name>
\d <table_name>
- Execute psql commands from a file
<file.sql>
\i <file.sql>
- Get help on psql commands
\?
\h CREATE TABLE
- Turn on query execution time
\timing
You use the same command \timing to turn it off.
- Quit psql
\q
You can run the shell commands in psql CLI via \! . For instance, to print the current working directory we write:
\! pwd
Build the Database
Note: Explore the dataset using any data analysis tool (Python+Pandas, Excel, Google Sheet, …etc) you have before building the database.
Another note: You do not need to create a new role/user. Just use the current role postgres.
The dataset are csv files and need to be imported into PostgreSQL tables.
To copy the values from csv files into the table, you need to use Postgres COPY method od data-loading. Postgres’s COPY comes in two separate variants, COPY and \COPY: COPY is server based, \COPY is client based. COPY will be run by the PostgreSQL backend (user “postgres”). The backend user requires permissions to read & write to the data file in order to copy from/to it. You need to use an absolute pathname with COPY. \COPY on the other hand, runs under the current $USER, and with that users environment. And \COPY can handle relative pathnames. The psql \COPY is accordingly much easier to use if it handles what you need. So, you can use the meta-command \COPY to import the data from csv files into PostgreSQL tables but you need to make sure that the primary keys and foreign keys are set according to the given ER diagram. You can learn more about ER diagrams from here.
Notice that you need to create tables before importing their data from files. You can detect the datatype of the column from its values.
- Create the database
social
-- Create Database
CREATE DATABASE social;
-- Switch to the Database
\c social;
-- add User table
CREATE TABLE IF NOT EXISTS Users(
userid INT PRIMARY KEY NOT NULL,
surname VARCHAR(50),
name VARCHAR(50),
age INT,
_timestamp timestamp,
temp BIGINT NOT NULL
);
-- add Post table
CREATE TABLE IF NOT EXISTS Posts(
postid INT PRIMARY KEY NOT NULL,
userid INT NOT NULL,
posttype VARCHAR(50),
posttimestamp timestamp,
temp BIGINT NOT NULL
);
-- add Friend table
CREATE TABLE IF NOT EXISTS Friends(
friend1 INT NOT NULL,
friend2 INT NOT NULL
);
-- add constrains
ALTER TABLE Friends
ADD CONSTRAINT fk_User_userid_friend1
FOREIGN KEY (friend1)
REFERENCES Users (userid);
ALTER TABLE Friends
ADD CONSTRAINT fk_User_userid_friend2
FOREIGN KEY (friend2)
REFERENCES Users (userid);
ALTER TABLE Posts
ADD CONSTRAINT fk_User_userid_userid
FOREIGN KEY (userid)
REFERENCES Users (userid);
- Upload the csv data into tables
\COPY Users(userid, surname, name, age, temp) FROM 'users.csv' DELIMITER ',' CSV HEADER;
UPDATE Users SET _timestamp = TO_TIMESTAMP(temp);
ALTER TABLE Users DROP COLUMN temp;
\COPY Posts(postid, userid, posttype, temp) FROM 'posts.csv' CSV HEADER;
UPDATE Posts SET posttimestamp = TO_TIMESTAMP(temp);
ALTER TABLE Posts DROP COLUMN temp;
\COPY Friends from 'friends.csv' csv header;
Fix Friends table
CREATE TABLE friends2 AS
SELECT friend1, friend2 FROM friends
UNION
SELECT friend2, friend1 FROM friends;
ALTER TABLE friends RENAME TO friends_old;
ALTER TABLE friends2 RENAMT TO friends;
Data Retrieval using SQL
In this part of the lab, we will practice on writing SQL queries to retrieve data from our database.
Data Retrieval from a single table
You can return data from a single table by using SELECT command. This kind of data retrieval is the simplest way to get data from a single table.
Exercises
- Who are the users who have posts?
SELECT DISTINCT userid
FROM posts;
- What are the posts of the users?
SELECT DISTINCT postid
FROM posts;
- Which posts published after 2012?
SELECT *
FROM posts
WHERE EXTRACT(YEAR FROM posttimestamp) > 2012;
- What is the oldest and recent dates of the posts?
SELECT MAX(posttimestamp), MIN(posttimestamp)
FROM posts;
- What are the top 5 most recent posts whose type is
Image?
SELECT *
FROM posts
WHERE posttype='Image'
ORDER BY posttimestamp DESC
LIMIT 5;
- Which top 5 users who posted an
ImageorVideorecently?
SELECT userid, posttype
FROM posts
WHERE posttype IN ('Image', 'Video')
ORDER BY posttimestamp DESC
LIMIT 5;
- What is the age of the eldest and youngest persons?
SELECT MAX(age), MIN(age)
FROM users;
UPDATE users
SET age = CASE
WHEN age < 0 THEN -age
ELSE age
END;
In PostgreSQL, double quotes "" are used to indicate identifiers within the database, which are objects like tables, column names, and roles. In contrast, single quotes '' are used to indicate string literals.
Data Retrieval from multiple tables (Joining tables)
Exercises
- Who is the 2nd youngest person who published
Imageposts?
SELECT DISTINCT name, surname, age, posttype
FROM posts
JOIN users ON posts.userid = users.userid
WHERE posts.posttype='Image'
ORDER BY age ASC
LIMIT 1
OFFSET 1;
- What are the posts that are published by people who are between 20 and 30?
SELECT postid, posttype, age, users.userid
FROM posts
JOIN users ON posts.userid = users.userid
WHERE age <@ int4range(20, 30)
ORDER BY age;
- What are the friends of the youngest person?
WITH youngest AS(
SELECT userid
FROM users
ORDER BY age
ASC LIMIT 1
)
SELECT friend1 AS user, friend2 AS friend
FROM youngest, friends
JOIN users ON friends.friend1 = users.userid
WHERE users.userid = youngest.userid;
- How many friends for the surname
Thronton?
SELECT COUNT(friend2)
FROM users
JOIN friends ON (users.userid = friends.friend1)
WHERE users.surname = 'Thronton';
Aggregation and grouping
Exercises
- How many posts for each user?
SELECT users.userid, COUNT(*) as c
FROM users
JOIN posts ON (users.userid = posts.userid)
GROUP BY users.userid
ORDER BY c DESC;
- Who are the friends of users who posted
Image?
SELECT DISTINCT u2.userid, u2.name, u2.surname, u2.age, u.userid, u.name, u.surname
FROM users u
JOIN friends f ON f.friend1 = u.userid
JOIN posts ON posts.userid = u.userid
JOIN users u2 ON f.friend2 = u2.userid
WHERE posts.posttype = 'Image';
- How many friends of users whose age is less than 20?
SELECT COUNT(DISTINCT f1.friend2) as c
FROM users u
JOIN friends f1 ON (u.userid = f1.friend1)
WHERE u.age < 20;
- How many friends of friends of users whose age is less than 20?
SELECT COUNT(DISTINCT f2.friend2) as c
FROM users u
JOIN friends f1 ON (u.userid = f1.friend1)
JOIN friends f2 ON (f1.friend2 = f2.friend1)
WHERE u.age < 20 AND f2.friend2 <> u.userid;
- How many users have more than 10 posts?
WITH users_10_posts AS (
SELECT posts.userid, COUNT(*) as c
FROM posts
GROUP BY posts.userid
HAVING COUNT(*) > 10
)
SELECT COUNT(*) as c
FROM users_10_posts;
- What is the average number of posts published at noon and by the friends of the users whose age is more than 40? Calculate the percentage of posts.
WITH post_count AS (
SELECT COUNT(posts.postid) AS c
FROM users u
JOIN friends f ON f.friend1 = u.userid
JOIN posts ON posts.userid = f.friend1
JOIN users u2 ON f.friend1 = u2.userid
WHERE EXTRACT(HOUR FROM u2._timestamp) = 12 AND u.age > 40
)
SELECT AVG(c)
FROM post_count;
- What is the percentage of posts published at noon and by the friends of the users whose age is more than 40?
WITH post_count AS (
SELECT COUNT(posts.postid) AS c
FROM users u
JOIN friends f ON f.friend1 = u.userid
JOIN posts ON posts.userid = f.friend1
JOIN users u2 ON f.friend1 = u2.userid
WHERE EXTRACT(HOUR FROM u2._timestamp) = 12 AND u.age > 40) ,
post_total AS (
SELECT COUNT(*) as c2
FROM posts
)
SELECT 100 * c/c2 || '%'
FROM post_total, post_count;
Graph databases
A graph database is a database designed to store and manage data as a network of nodes (entities) and relationships (connections). Unlike traditional relational databases, where relationships are inferred through joins, graph databases store relationships as first-class citizens, enabling efficient traversal and querying. Graph databases use graph theory principles to structure data, making them ideal for representing highly connected information.
Graph databases are optimized for relationship-heavy data structures, where connections between entities are as important as the entities themselves. Unlike relational databases, which require complex JOIN operations to connect tables, graph databases enable direct relationship traversal.
Download and Install Memgraph
You can download the Docker image for Memgraph and run a container. You can find more detail in this official page. Memgraph comes with different Docker images. The main repositories that contain memgraph are:
memgraph/memgraph-mage- includes Memgraph database, command-line interfacemgconsoleand MAGE graph algorithms library. If tagged with cuGraph, it also includes NVIDIA cuGraph GPU-powered graph algorithms.memgraph/memgraph- includes Memgraph database and command-line interfacemgconsole.
There are also two additional standalone images that do not include the Memgraph:
memgraph/lab- includes a web interface Memgraph Lab that helps you explore the data stored in Memgraph.memgraph/mgconsole- includes a command-line interface mgconsole that allows you to interact with Memgraph from the command line.
For this lab, you can just need two containers. One is the graph engine and another the web user interface. You can run a multi-container memgraph as follows:
services:
memgraph:
image: memgraph/memgraph-mage:latest
container_name: memgraph-mage
ports:
- "7687:7687"
- "7444:7444"
command: ["--log-level=TRACE"]
lab:
image: memgraph/lab:latest
container_name: memgraph-lab
ports:
- "3001:3000"
depends_on:
- memgraph
environment:
- QUICK_CONNECT_MG_HOST=memgraph
- QUICK_CONNECT_MG_PORT=7687
You can just put this content in a file docker-compose.yaml and then run it using docker compose up -d. Then you can open the Memgraph lab (http://localhost:3001) in the browser to access the web UI as shown below.

You can also access the console of the graph if you selected to not use the Memgraph lab web UI as follows:
docker exec -it memgraph-mage mgconsole
This will open the console for Memgraph where you can write your queries in Cypher language.
Download and Install Neo4j (Optional)
Neo4j can be installed as an interpreter in Zeppelin but in HDP 2.6.5, Zeppelin 0.7.3 is installed and does not support neo4j interpreter. Installing Neo4j on HDP 2.6.5 as a Zeppelin interpreter will not work. The latest version (in Feb. 2025) of Zeppelin 0.11.0 supports Neo4j but we do not need to install it. Indeed, HDP 3.0 has Zeppelin 0.8.0 installed and supports neo4j interpreter but it is not a big deal to install HDP 3.0 just for neo4j since our work on the sandbox will not be mostly on graph databases.
The easy approach is to install Neo4j Desktop on your local machine. You can find here (https://neo4j.com/docs/desktop-manual/current/installation/download-installation/) some information about installing Neo4j Desktop and you can find here (https://neo4j.com/deployment-center) download links. After you start downloading, the website will give a long key you need to use when you install the software as follows:

The software will prepare the environment for installation as follows.

Installing Neo4j Desktop
When you succeed installation, it will show the following dashboard.

The less easy approach is to install Neo4j on your cluster node via yum OR offline via rpm. You can find here (https://yum.neo4j.com) some information about installing neo4j via yum and here (https://neo4j.com/docs/operations-manual/3.5/installation/linux/rpm/#linux-yum) some information about offline installation. After that, you can forward the port of the server to some custom port 10015 to the host machine in order to access Neo4j Browser (change this setting server.http.listen_address to 10015 in neo4j.conf file of the Neo4j DBMS instance).
If you want to install Neo4j on the cluster, you need to know that the old versions of Neo4j can be installed. I suggest the version 3.5.35.1 and you can see below the cypher shell dependencies.


You can access the guest machine in VirtualBox by ssh into the HostSSH port specified in the port forwarding rules which can be reached from the network settings of the virtual machine. You can also add your rules to the list.
Neo4j docker image
Neo4j has docker image in dockerhub for the Neo4j database server. You can follow this approach to run the server as a docker container and access the service from the browser. Make sure that you have installed Docker engine and docker daemon is working. You can pull the image as follows:
docker pull neo4j
![]()
You can run the Neo4j server as a container:
docker run --name neo4j_server --publish=7474:7474 --publish=7687:7687 --volume /neo4j/logs:/var/lib/neo4j/logs --volume /neo4j/import:/var/lib/neo4j/import --volume /neo4j/plugins:/var/lib/neo4j/plugins --volume /neo4j/data:/var/lib/neo4j/data --env NEO4J_AUTH=neo4j/neo4jneo4j neo4j
The command above will create and run a docker container neo4j with name neo4j_server and publish ports 7474 for http and 7687 for bolt protocols. It will also attach volumes for logs, import, plugins and data folders. The env option will assign the password neo4jneo4j for the default user neo4j. You can use -d or --detach option to let the server run in detached mode in the background.
You can stop the container when you are done as follow:
docker stop neo4j_server
Where neo4j_server is the container name or id if you did not assign a name.
You can start the container again as follows:
docker start neo4j_server
Where neo4j_server is the container name or id if you did not assign a name.
In case you want to change some of the settings in running the container then you can delete the container and create a new one. Your data inside can be stored in local file system by attaching volumes to folders you want to. You can delete the container as follows: (make sure that you stopped it)
docker rm neo4j_server
Where neo4j_server is the container name or id if you did not assign a name.
You can access the Neo4j Browser usually at http://localhost:7474.
If you can not install Neo4j due to some reason, you can open a free session of Neo4j Sandbox at https://neo4j.com/sandbox/ but you need proxy.
Cypher
Cypher is a graph database query language that allows users to store and retrieve data from the graph database. It is a declarative, SQL-inspired language for describing visual patterns in graphs. The syntax provides a visual and logical way to match patterns of nodes and relationships in the graph. Cypher keywords are not case-sensitive but it is case-sensitive for variables.
Neo4j
All Neo4j servers contain a built-in database called system, which behaves differently than all other databases. The system database stores system data and you can not perform graph queries against it. A fresh installation of Neo4j includes two databases:
- system - the system database described above, containing meta-data on the DBMS and security configuration.
- neo4j - the default database, named using the config option dbms.default_database=neo4j.
Memgraph
Memgraph also provides with a default database in community edition named memgraph. You can use the same Cypher language to write and run queries in Memgraph. The difference is in some commands (e.g. loading data) and the functions supported by the engine. Neo4j provides APOC library that allows to access a huge set of functions useful for different purposes (data integration, graph algorithms, and data conversion.). Memgraph also provides functions and you can list all available functions by running CALL mg.functions() YIELD *;. Memgraph has a library called MAGE graph algorithm library that allows to access a set of functions for graph algorithms. Neo4j has a similar library called Graph Data Science (GDS).
Labeled Property Graph (LPG) model
Memgraph implements the Labeled Property Graph (LPG) model, a flexible and powerful way to structure data. LPG represents data as a graph of nodes (entities) and relationships (connections), both of which can have properties—key-value pairs storing additional information. This structure enables intuitive, high-performance queries without relying on complex joins, as in relational databases.

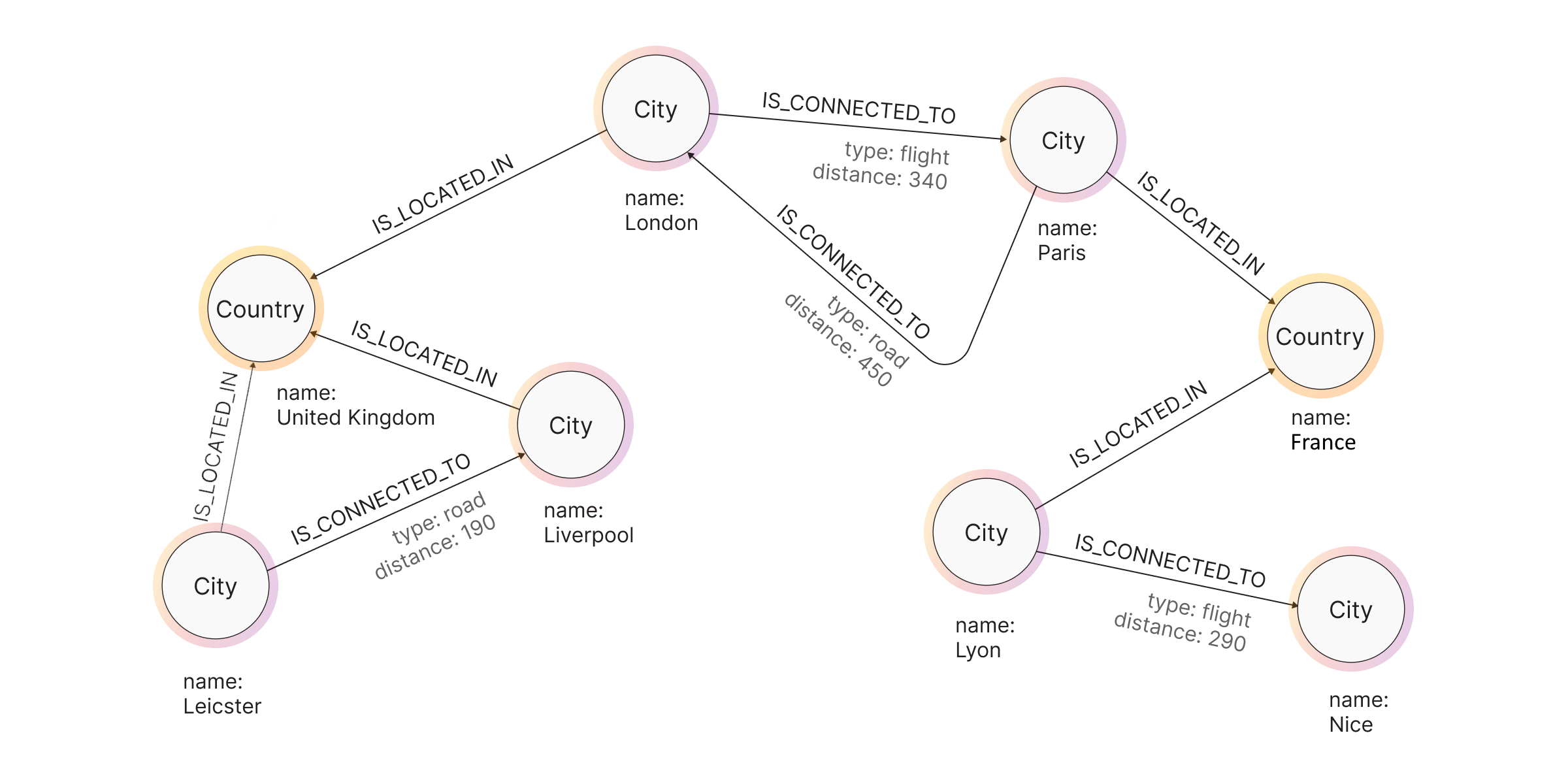
Examples of graph databases
Graph Components
A graph consists of three core components: nodes, relationships, and labels. Both nodes and relationships have properties.
Nodes
Nodes represent entities in your dataset. Each node can belong to one or multiple labels, which act as categories or types. Labels help define the role and grouping of nodes within the graph.
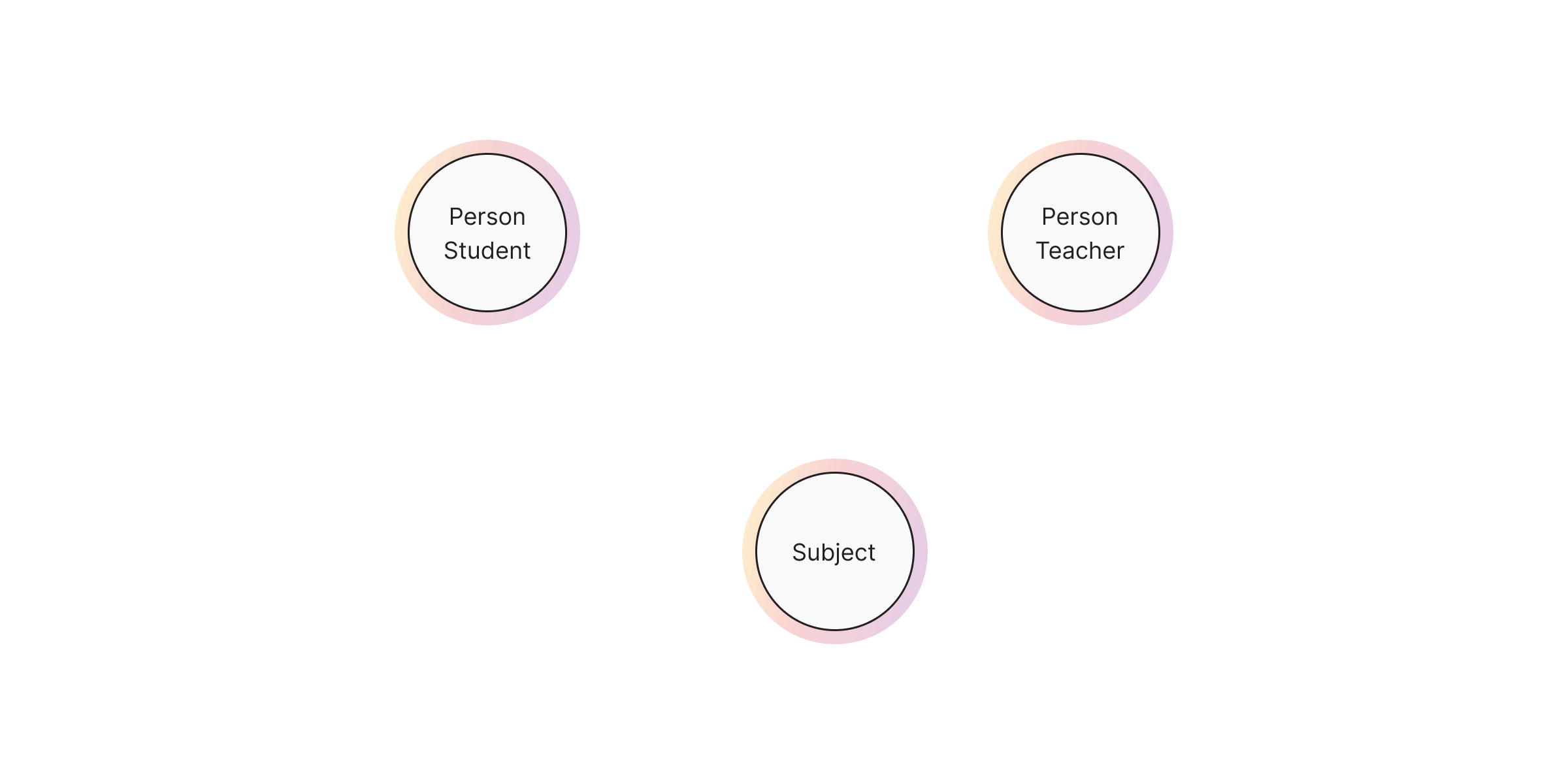
We can create this graph in Cypher as follows:
CREATE (:Person:Student {name: "Alice", age: 20})
CREATE (:Person:Teacher {name: "Mr. Smith", experience: 10})
CREATE (:Subject {name: "Mathematics"})
Naming Conventions
- Node labels should be written using CamelCase and start with an upper-case letter. Node labels are case-sensitive.
(:Country)
(:City)
(:CapitalCity)
- Property keys, variables, parameters, aliases, and functions are camelCase and begin with a lower-case letter. These components are case-sensitive.
dateOfBirth // Property key
largestCountry // Variable
size() // Function
countryOne // Alias
- Relationship types are styled upper-case and use the underscore character
_to separate multiple words. They are also case-sensitive.
[:LIVES_IN]
(:BORDERS_WITH)
- Aside from clauses, there is a number of keywords that should be styled with capital letters even though they are not case sensitive. These include:
DISTINCT,IN,STARTS WITH,CONTAINS,NOT,AND,ORandAS.
MATCH (c:Country)
WHERE c.name CONTAINS 'United' AND c.population > 9000000
RETURN c AS Country;
Relationships
Relationships define connections between nodes. They are directed, meaning they always have a start node and an end node, but queries can traverse them in any direction.
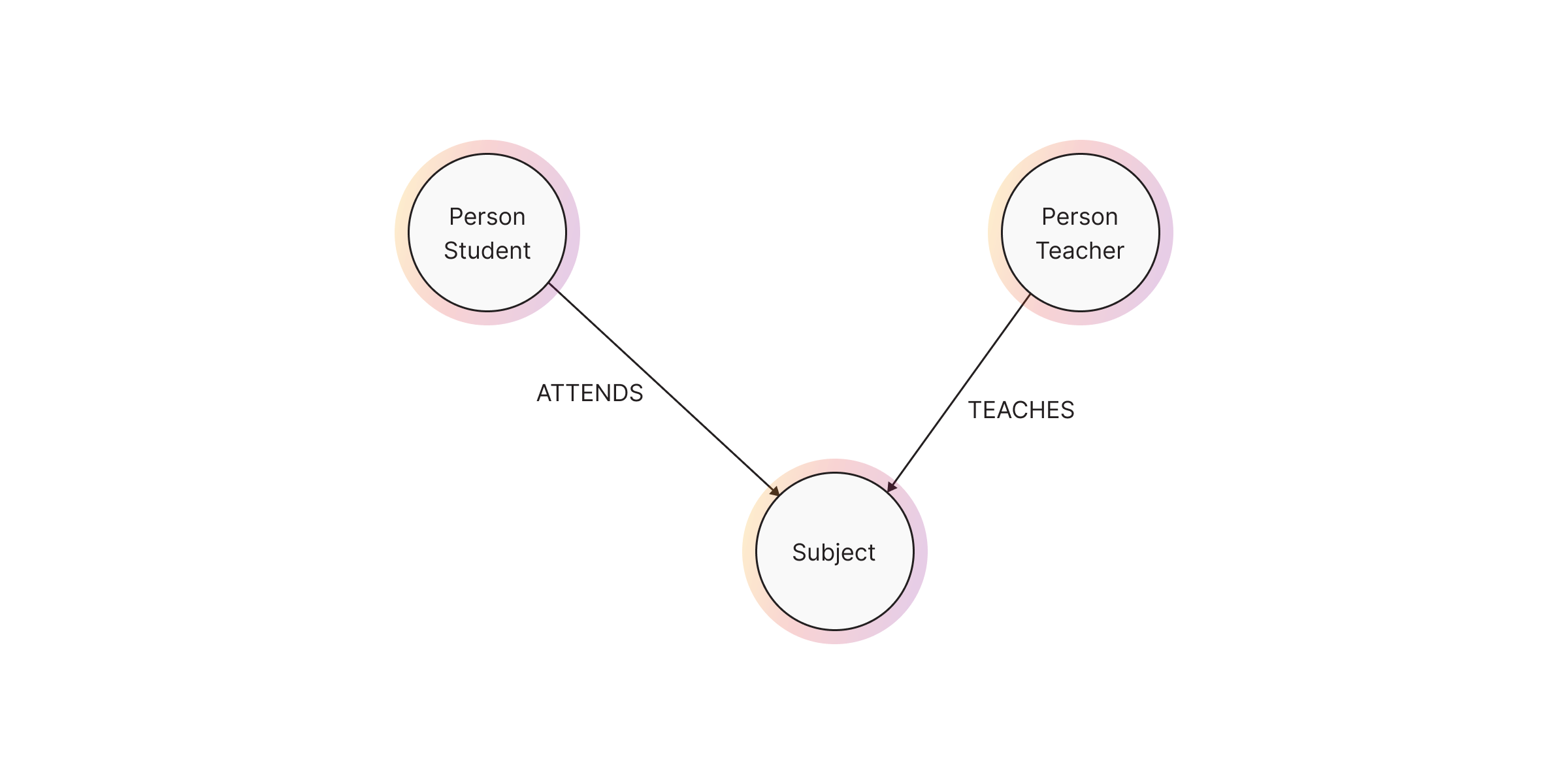
In Cypher:
MATCH (T:Person:Teacher {name: "Mr. Smith"})
MATCH (S:Subject {name: "Mathematics"})
MATCH (ST:Person:Student {name: "Alice"})
// CREATE (T)-[:TEACHES]->(S)
// CREATE (ST)-[:ATTENDS {grade: "A"}]->(S)
CREATE (T)-[:TEACHES]->(S)<-[:ATTENDS {grade: "A"}]-(ST)
Labels
Labels categorize nodes and make querying more efficient. A node can have multiple labels, allowing for flexible classification.
| Node | Label(s) | Properties |
|---|---|---|
Person:Student |
Person, Student |
name, dateOfBirth, yearOfStudy |
Person:Teacher |
Person, Teacher |
name, email, age |
Subject |
Subject |
name |

MATCH (p:Person:Student) RETURN p.name;
Properties
Both nodes and relationships can have properties, which store structured data within the graph. Properties use key-value pairs and store metadata inside nodes and relationships.
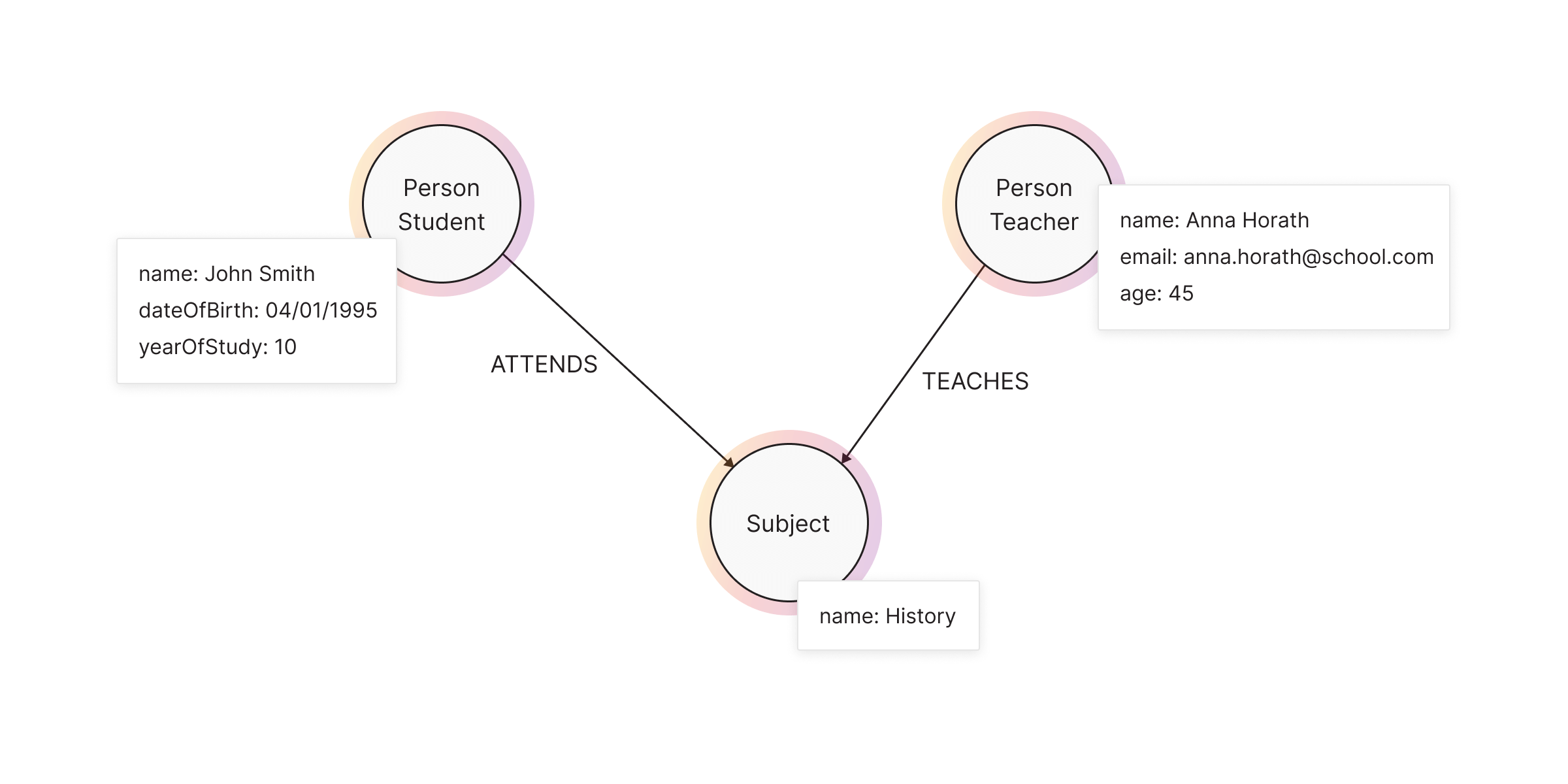
The LPG model consists of mainly nodes and relationships. Nodes are the entities in the graph.
- Nodes can be tagged with labels, representing their different roles in your domain. (For example, Person).
- Nodes can hold any number of key-value pairs, or properties. (For example, name).
- Node labels may also attach metadata (such as index or constraint information) to certain nodes.
Whereas relationships provide directed, named, connections between two node entities (e.g. Student ATTENDS Subject).
- Relationships always have a direction, a type, a start node, and an end node, and they can have properties, just like nodes.
- Nodes can have any number or type of relationships without sacrificing performance.
- Although relationships are always directed, they can be navigated efficiently in any direction.
Property types
The following data types are included in the property types category: Integer, Float, String, Boolean, Point, Date, Time, LocalTime, DateTime, LocalDateTime, and Duration. For more details, visit the Memgraph documentation and Neo4j documentation.
Structural types
The following data types are included in the structural types category: Node, Relationship, and Path.
- The Node data type includes: Id, Label(s), and Map (of properties). Note that labels are not values, but a form of pattern syntax. A label is of the type
String. - The Relationship data type includes: Id, Type, Map (of properties), Id of start node, and Id of end node. Type is also represented in the form of a
String. - The Path data type is an alternating sequence of nodes and relationships.
Nodes, relationships, and paths are returned as a result of pattern matching. In Neo4j, all relationships have a direction. However, you can have the notion of undirected relationships at query time. For example, to retrieve all undirected relationships of type TEACHES, we can write in Cypher the following:
MATCH ()-[s:TEACHES]-() RETURN s
Composite types
The following data types are included in the composite types category: List and Map.
RETURN [1,2,3,4,5], {id:1, msg: 'hello', age: 31}
How to define a variable
When you reference parts of a pattern or a query, you do so by naming them. The names you give the different parts are called variables.
In this example:
MATCH (n)-->(b)
RETURN b
The variables are n and b.
// this is a comment
A comment begin with double slash (//) and continue to the end of the line. Comments do not execute, they are for humans to read.
Operators
DISTINCT (aggregation operator)
WITH ['a', 'a', 4, 'b', 4] AS ps
UNWIND ps AS p
RETURN DISTINCT p
The output will have only ‘a’, 4, and ‘b’.
Property operators
The operator . statically access the property of a node or relationship.
The operator [] is used for filtering on a dynamically-computed property key and accessing list items.
Example:
CREATE
(a:Restaurant {name: 'Hungry Jo', rating_hygiene: 10, rating_food: 7}),
(b:Restaurant {name: 'Buttercup Tea Rooms', rating_hygiene: 5, rating_food: 6}),
(c1:Category {name: 'hygiene'}),
(c2:Category {name: 'food'})
WITH a, b, c1, c2
MATCH (restaurant:Restaurant), (category:Category)
WHERE restaurant["rating_" + category.name] > 6
RETURN DISTINCT restaurant.name
The operator = used for replacing all properties of a node or relationship
CREATE (a:Person {name: 'Jane', age: 20})
WITH a
MATCH (p:Person {name: 'Jane'})
SET p = {name: 'Ellen', livesIn: 'London'}
RETURN p.name, p.age, p.livesIn
Mathemtical operators
The mathematical operators comprise:
- addition: +
- subtraction or unary minus: -
- multiplication: *
- division: /
- modulo division: %
- exponentiation: ^
RETURN ((2*4+200/50)%7)
// 25
Comparison operators
The comparison operators comprise:
- equality: =
- inequality: <>
- less than: <
- greater than: >
- less than or equal to: <=
- greater than or equal to: >=
- IS NULL
- IS NOT NULL
String-specific comparison operators comprise:
- STARTS WITH: perform case-sensitive prefix searching on strings
- ENDS WITH: perform case-sensitive suffix searching on strings
- CONTAINS: perform case-sensitive inclusion searching in strings
- =~: regular expression for matching a pattern
WITH [['mouse', 'chair', 'door', 'house'], ['house', 'house', 'window', 'door']] AS listwordlist
UNWIND listwordlist AS wordlist
UNWIND wordlist AS word
WITH word
WHERE word =~ '.*ous.*'
RETURN word
Boolean operators
The boolean operators — also known as logical operators — comprise: AND, OR, XOR, NOT.
RETURN NOT 4>23 XOR 2>1;
// false
String operators
The string operators comprise: concatenating strings: +
RETURN 'neo' + '4j' AS result
Check other operators from the documentation.
Patterns
Patterns and pattern-matching are at the very heart of Cypher, so being effective with Cypher requires a good understanding of patterns.
Using patterns, you describe the shape of the data you are looking for. For example, in the MATCH clause you describe the shape with a pattern, and Cypher will figure out how to get that data for you.
The pattern describes the data using a form that is very similar to how one typically draws the shape of property graph data on a whiteboard: usually as circles (representing nodes) and arrows between them to represent relationships.
Patterns appear in multiple places in Cypher: in MATCH, CREATE and MERGE clauses, and in pattern expressions.
Patterns for nodes
This simple pattern describes a single node, and names that node using the variable a.
MATCH (node) RETURN node;
Patterns for related nodes
This pattern describes a very simple data shape: two nodes, and a single relationship from one to the other.
MATCH (node1)-[connection]-(node2) RETURN node1, connection, node2;
This manner of describing nodes and relationships can be extended to cover an arbitrary number of nodes and the relationships between them, for example:
MATCH p = (node1)-[connection]-(node2)-[connection2]-(node3)
RETURN p;
Such a series of connected nodes and relationships is called a “path”.
Build the database in Neo4j Desktop
In Neo4j Desktop, create a new project as follows:

and add a local DBMs to the new project. Then, start the database as follows:

As you can see in the following screenshot, the database is active and we can access it as a default user neo4j by opening a dashboard with Neo4j Browser.

In order to load csv files to the database, you need to add them to the import of the database (do not add them to the project directory) as follows:

After copying/pasting the csv files, the import directory will be as follows:

Using Neo4j installed via Docker
This image is related to the community edition of Neo4j and you cannot create a new database but you can load files as follows. You need to find the folder import inside the Neo4j server container where you have to put your files. By default, the path in the container is /var/lib/neo4j/import. You can copy your files there using docker cp.
Using Memgraph installed via Docker
Here you also cannot create more than the default database memgraph if you do not have the enterprise edition. You can import the dataset files into the database using docker cp and there is no specific folder to put the files in. So, I will assume that you will put the files in the directory /var/lib/memgraph/ or maybe you can access the container using bash and create a directory/repository for importing data like /var/lib/memgraph/data. Let’s follow the latter approach.
- Access the container via
bash.
docker exec -it memgraph-mage bash
- Create the folder
mkdir -p /var/lib/memgraph/data
# You can also run one line for the steps above
# docker exec -it memgraph-mage bash -c "mkdir -p /var/lib/memgraph/data"
- Import the data using
docker cp.
docker cp <path-to-your-file-in-local-machine> memgraph-mage:/var/lib/memgraph/data/
Data loading and creating nodes/relationships
Each of the 3 CSV files needs to be loaded into Neo4j using the LOAD CSV command that reads each row of the file and then assigns the imported values to the nodes and edges of the graph.
The instructions for Neo4j here are a little different than Memgraph but for the queries in the next sections it is the same.
// Memgraph
// Create Index for users on userid field
CREATE INDEX ON :User(userid);
// Neo4j
// Create Index for users on userid field
CREATE INDEX FOR (u:User) ON (u.userid)
// Memgraph
// Create Index for posts on postid field
CREATE INDEX ON :Post(postid);
// Neo4j
// Create Index for posts on postid field
CREATE INDEX FOR (u:Post) ON (u.postid)
// Memgraph
// Load users data
LOAD CSV FROM "/var/lib/memgraph/data/users.csv"
WITH HEADER DELIMITER "," AS row
WITH row, toInteger(row.timestamp) AS epoch_seconds
CALL date.format(epoch_seconds, "s", "%Y-%m-%dT%H:%M:%S") YIELD formatted
CREATE (:User {
userid: toInteger(row.userid),
name: row.name,
surname: row.surname,
age: toInteger(row.age),
timestamp: localDateTime(formatted)
});
// Neo4j
// Load users data
LOAD CSV WITH HEADERS
FROM "file:///users.csv" AS row
FIELDTERMINATOR ','
CREATE (
:User {
userid: toInteger(row['userid']),
name:row['name'],
surname: row['surname'],
age: toInteger(row['age']),
timestamp: datetime({epochSeconds: toInteger(row['timestamp'])})}
);
// Memgraph
// Load posts data
LOAD CSV FROM "/var/lib/memgraph/data/posts.csv"
WITH HEADER DELIMITER "," AS row
CALL date.format(toInteger(row['posttimestamp']),"s", "%Y-%m-%dT%H:%M:%S") YIELD formatted
MATCH (u:User{userid:toInteger(row['userid'])})
MERGE (
:Post {
postid: toInteger(row['postid']),
userid: toInteger(row['userid']),
posttype:row['posttype']
})<-[:ADD{
posttimestamp: localDateTime(formatted)
}]-(u);
// Neo4j
// Load posts data
LOAD CSV WITH HEADERS
FROM "file:///posts.csv" AS row
FIELDTERMINATOR ','
MATCH (u:User{userid:toInteger(row['userid'])})
MERGE (
:Post {
postid: toInteger(row['postid']),
userid: toInteger(row['userid']),
posttype:row['posttype']
})<-[:ADD{
posttimestamp: datetime({epochSeconds: toInteger(row['posttimestamp'])})
}]-(u);
// Same for Neo4j/Memgraph
// Retrieve some nodes
MATCH (n)
RETURN n
LIMIT 10;
// Memgraph
// Load Friends
USING PERIODIC COMMIT 1000 // loads 1000 rows per batch
LOAD CSV FROM "/var/lib/memgraph/data/friends.csv"
WITH HEADER DELIMITER "," AS row
MATCH (u:User{userid:toInteger(row['friend1'])})
MATCH (v:User{userid:toInteger(row['friend2'])})
MERGE (u)-[:FRIEND]->(v)-[:FRIEND]->(u)
// Neo4j
// Load Friends
:auto USING PERIODIC COMMIT
LOAD CSV WITH HEADERS
FROM "file:///friends.csv" AS row
FIELDTERMINATOR ','
MATCH (u:User{userid:toInteger(row['friend1'])})
MATCH (v:User{userid:toInteger(row['friend2'])})
MERGE (u)-[:FRIEND]->(v)-[:FRIEND]->(u)
Data Retrieval with Cypher
All Cypher queries here can run on both engines Neo4j and Memgraph.
Cypher is a graph query language that lets you retrieve data from the graph. It is like SQL for graphs, and was inspired by SQL so it lets you focus on what data you want out of the graph (not how to go get it). It is the easiest graph language to learn by far because of its similarity to other languages and intiutiveness.
Exercises
- Who are the users who have posts?
// MATCH (u:User)-[:ADD]-()
MATCH (u:User)
RETURN DISTINCT u
LIMIT 10 // This is added just to not display all nodes
// COUNT
MATCH (u:User)
RETURN COUNT(DISTINCT u)
- How many posts of the first 10 users?
MATCH (u:User)
WITH u LIMIT 10
MATCH path = (u)-[:ADD]->(p:Post)
WITH u, COUNT(p) AS posts
ORDER BY posts DESCENDING // 117
RETURN u, posts
This will return the number of posts added by the first 10 users sorted in descending order of the their number of posts.
- Which posts published after 2012?
MATCH (p:Post)<-[a:ADD]-()
WHERE a.posttimestamp.year > 2012
RETURN p
LIMIT 10 // This is added just to not display all nodes
- What is the oldest and recent dates of the posts?
MATCH (p:Post)-[a:ADD]-()
RETURN MAX(a.posttimestamp), MIN(a.posttimestamp)
- What are the top 5 most recent posts whose type is
Image?
MATCH (p:Post{posttype:"Image"})-[a:ADD]-()
RETURN p, a
ORDER BY a.posttimestamp DESC
LIMIT 5
- Which top 5 users who posted an
ImageorVideorecently?
MATCH (u:User)-[a:ADD]->(p:Post)
WHERE p.posttype IN ["Image", "Video"]
RETURN u, p
ORDER BY a.posttimestamp
LIMIT 5
- What is the age of the eldest and youngest persons?
MATCH (u:User)
RETURN MAX(u.age), MIN(u.age)
// Update the age of the person
MATCH (u:User)
SET u.age = CASE
WHEN u.age < 0 THEN -u.age
ELSE u.age
END
- Who is the 2nd youngest person who published
Imageposts?
MATCH (u:User)-[:ADD]->(p:Post{posttype:"Image"})
RETURN DISTINCT u.name, u.surname, u.age, p.posttype
ORDER BY u.age ASC
SKIP 1
LIMIT 1
- What are the posts that are published by people who are between 20 and 30?
MATCH (p:Post)<-[:ADD]-(u:User)
WHERE u.age IN range(20, 30)
RETURN p.postid, p.posttype, u.age, u.userid
ORDER BY u.age
- What are the friends of the youngest person?
CALL{
MATCH (u:User)
RETURN u.userid AS youngest
ORDER BY u.age ASC
LIMIT 1
}
WITH youngest
MATCH (u:User{userid:youngest})-[:FRIEND]-(f1:User)
RETURN DISTINCT u.userid AS user, f1.userid AS friend
- How many friends for the surname
Thronton?
MATCH (u:User{surname:"Thronton"})-[:FRIEND]-(f1:User)
RETURN COUNT(DISTINCT f1)
- How many posts for each user?
MATCH (u:User)--(p:Post)
RETURN u.userid AS user, COUNT(*) AS c
ORDER BY c DESC
- Who are the friends of users who posted
Image?
MATCH (f:User)--(u:User)--(:Post{posttype:"Image"})
RETURN DISTINCT u.userid, u.name, u.surname, f.userid, f.name, f.surname, f.age
- How many friends of users whose age is less than 20?
MATCH (u:User)--(f1:User)
WHERE u.age < 20
RETURN COUNT(DISTINCT f1.userid) AS c
- How many friends of friends of users whose age is less than 20?
MATCH (u:User)-[:FRIEND*2]-(f2:User)
WHERE u.age < 20 AND f2.userid <> u.userid
RETURN COUNT(DISTINCT f2.userid) AS c
- How many users have more than 10 posts?
- What is the average number of posts published at noon and by the friends of the users whose age is more than 40? Calculate the percentage of posts.
- What is the percentage of posts published at noon and by the friends of the users whose age is more than 40?
Common issues
- When you try to access the database by running the command
psql -U postgresas[root@sandbox-hdp data]# psql -U postgres. You may get the following error:psql: FATAL: Peer authentication failed for user “postgres”
- Possible reasons:
- The database is configured to allow access only through the credentials of the user.
- Possible solutions:
- You can change this configuration to allow all users to access the database without the need to enter credentials. Add the line
local all all trustat the beginning of the file/var/lib/pgsql/data/pg_hba.confthen restart PostgreSQL service by running the commandsystemctl restart postgresqlas root user.
- You can change this configuration to allow all users to access the database without the need to enter credentials. Add the line
- Possible reasons:
NB: If you have other issues, please contact the TA.
References
- PostgreSQL cheatsheet
- Yasin N. Silva, Isadora Almeida, and Michell Queiroz. 2016. SQL: From Traditional Databases to Big Data. In Proceedings of the 47th ACM Technical Symposium on Computing Science Education (SIGCSE '16). Association for Computing Machinery, New York, NY, USA, 413–418. https://doi.org/10.1145/2839509.2844560
- Comprehensive PostgreSQL Tutorial
- psql 9.2 Documentation
- Cypher Manual